




This extensive resource acts as a comprehensive guide for software developers aiming to transition into the burgeoning field of generative AI product development, particularly focusing on large language models.
It meticulously outlines the essential foundational knowledge in areas like machine learning, deep learning, NLP, and the Transformer architecture, alongside crucial advanced competencies such as LLM fine-tuning, prompt engineering, Retrieval-Augmented Generation, and responsible AI practices.
The text also examines the unique aspects of the LLM product development lifecycle, from ideation to deployment and optimization, while providing insights into the generative AI ecosystem, including key players, emerging trends, and regulatory considerations.
Ultimately, it synthesizes this information into a strategic roadmap with actionable steps for career advancement, culminating in a ranking of the top 25 critical subareas for aspiring generative AI developers.
1. Introduction: Charting the Course into Generative AI
The advent of generative artificial intelligence (AI), particularly driven by large language models (LLMs), represents a paradigm shift in technology, comparable in potential impact to the internet or mobile computing. This domain, characterized by AI systems capable of creating novel content such as text, images, code, or audio based on patterns learned from vast datasets [1, 2, 3, 4, 5], is rapidly reshaping industries and creating unprecedented opportunities, especially for software developers. However, transitioning into the role of a developer focused on LLM-based products or services requires navigating a complex landscape of new technologies, methodologies, and career strategies. This article provides a comprehensive, Ph.D.-level analysis of the critical subareas a developer must master for a successful career transition into this dynamic field. It defines key concepts, explores essential technical competencies, examines the unique product development lifecycle, analyzes the industry ecosystem, and outlines effective transition strategies, culminating in a synthesized ranking of the top 25 most critical subareas for aspiring generative AI developers.
1.1. Defining the Terrain: Key Concepts
Understanding the core terminology is paramount for navigating this transition:
Generative AI (GenAI): A subset of artificial intelligence focused on models that generate new data artifacts (text, images, etc.) rather than solely analyzing or classifying existing data. [1, 3, 4] These systems learn underlying patterns and structures from training data, often using unsupervised or self-supervised learning techniques with architectures like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), or Transformers. [4, 6] GenAI is distinguished by its ability to mimic or extend human creativity. [3]
LLM-based Product or Service: An application or system whose core functionality leverages a Large Language Model. LLMs are deep learning models, typically based on the Transformer architecture [7, 8], trained on massive text datasets to understand and generate human-like language. [9, 10] Products range from sophisticated chatbots and virtual assistants [11, 12] to content generation tools (articles, marketing copy, code) [7, 11, 13], translation services [7, 11], sentiment analysis tools [7, 11], AI-powered search [7], and domain-specific applications in fields like healthcare, finance, and law. [12, 13]
Developer Role (Generative AI/LLM Focus): This role involves designing, developing, implementing, and managing AI systems, specifically those leveraging generative models like LLMs. [6, 14, 15] Responsibilities extend beyond traditional software engineering to include selecting or fine-tuning foundation models, developing and maintaining AI pipelines (data preprocessing, training, evaluation, deployment), prompt engineering, integrating models with external data sources (e.g., via RAG), ensuring responsible AI practices, collaborating with data scientists and product managers, and staying abreast of rapid advancements. [6, 14, 15, 16, 17] The role often requires expertise in specific AI frameworks (TensorFlow, PyTorch), libraries (Hugging Face Transformers, LangChain), and cloud platforms. [6, 14, 15]
Successful Career Transition: Moving from a prior role (often traditional software development) into a generative AI developer position, characterized by acquiring the necessary skills, securing relevant employment, performing effectively, and establishing a trajectory for growth within the GenAI field. [18, 19] Success implies not just technical proficiency but also adaptability, continuous learning, strategic portfolio building, effective networking, and the ability to leverage AI tools to enhance productivity and tackle complex problems. [18, 19, 20] This transition occurs within a context of significant potential workforce disruption, where GenAI may automate certain tasks but also augment human capabilities and create new, higher-value roles. [18, 21, 22]
2. Laying the Groundwork: Foundational Knowledge and Technical Skills
A successful transition into generative AI development necessitates a robust technical foundation, building upon but significantly extending traditional software engineering skills. Mastery of these core areas is non-negotiable.
2.1. Programming Prowess: Python as the Lingua Franca
Python has emerged as the dominant language for AI and machine learning development due to its simplicity, readability, extensive ecosystem of libraries, and strong community support.[20, 23, 24, 25] Proficiency in Python is essential, including a solid grasp of data structures, algorithms, object-oriented programming, and standard libraries.[6] Crucially, developers must master key AI/ML libraries:
NumPy & Pandas: For numerical computation and data manipulation, respectively – fundamental for handling the datasets involved in ML workflows.[20, 24]
Scikit-learn: A foundational library for traditional machine learning algorithms (regression, classification, clustering), essential for understanding core ML concepts and often used for baseline models or specific pipeline components.[26, 27, 28]
TensorFlow & PyTorch: The two leading deep learning frameworks. Developers must gain proficiency in at least one, preferably both, to build, train, and deploy neural networks, including the complex architectures underpinning LLMs.[6, 14, 15, 20, 23, 24, 26, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38] Familiarity with their APIs (like
tf.keras[30]) and ecosystem tools is vital. While other languages like R, Java, or C++ have niche applications in AI [29], Python remains the primary language for LLM development.
2.2. Machine Learning Fundamentals: The Conceptual Bedrock
A deep understanding of core machine learning principles is indispensable before tackling advanced generative models. This includes:
Supervised Learning: Concepts like regression (predicting continuous values) and classification (predicting discrete categories), including algorithms like linear regression, logistic regression, support vector machines, and decision trees.[26, 27, 28, 39] Understanding the training process, cost functions, and gradient descent is fundamental.[28]
Unsupervised Learning: Techniques like clustering (grouping similar data points) and dimensionality reduction (reducing the number of features), which are relevant for data exploration and sometimes feature engineering.[26, 27, 28, 39]
Model Evaluation: Understanding metrics like accuracy, precision, recall, F1-score, and AUC, and concepts like overfitting, underfitting, bias-variance trade-off, and cross-validation are critical for assessing and improving model performance.[17, 28]
Data Handling: Proficiency in data preprocessing (cleaning, normalization, handling missing values), feature engineering (creating relevant input features for models), and managing large datasets is essential, as data quality significantly impacts model performance.[14, 15, 17, 19, 25, 29, 34, 38, 40]
2.3. Deep Learning Concepts: Powering Modern AI
LLMs are a product of deep learning, requiring developers to grasp its core ideas:
Neural Networks: Understanding the basic structure (layers, neurons, activation functions) and the training process (backpropagation, gradient descent).[14, 15, 26, 28, 29, 32, 39]
Key Architectures: Familiarity with Convolutional Neural Networks (CNNs) for image processing and Recurrent Neural Networks (RNNs), including LSTMs, for sequential data, provides context for the evolution towards Transformers.[23, 26, 41]
Training Techniques: Understanding concepts like hyperparameter tuning, regularization (e.g., dropout, weight decay) to prevent overfitting, and optimization algorithms (e.g., Adam).[17, 32, 37, 39, 41]
2.4. Natural Language Processing (NLP) Essentials
Since LLMs operate on language, a foundation in NLP is crucial:
Text Preprocessing: Techniques like tokenization (breaking text into words or subwords), stemming, lemmatization, and stop-word removal.[10, 42] Understanding how LLMs use specific tokenizers is vital.[8]
Embeddings: Representing words or text as numerical vectors that capture semantic meaning (e.g., Word2Vec, GloVe, and contextual embeddings from models like BERT).[8, 25, 43] Understanding embeddings is key to grasping how LLMs process input and how vector databases perform semantic search.
Core NLP Tasks: Familiarity with tasks like text classification, sentiment analysis, named entity recognition (NER), machine translation, and question answering provides context for LLM applications.[14, 15, 20, 23, 42, 44, 45]
2.5. Transformer Architecture: The Engine of LLMs
The Transformer architecture, introduced in the "Attention Is All You Need" paper [46, 47], revolutionized NLP and powers most modern LLMs.[7, 8, 46, 47, 48, 49] Developers must understand its key components:
Self-Attention Mechanism: The core innovation allowing the model to weigh the importance of different words in the input sequence relative to each other, capturing long-range dependencies effectively.[7, 8, 43, 44, 46, 47]
Encoder-Decoder Structure: The original architecture (though many LLMs are decoder-only) involving processing the input sequence (encoder) and generating the output sequence (decoder).[46, 47]
Multi-Head Attention: Running the attention mechanism multiple times in parallel to capture different types of relationships.[50]
Positional Encoding: Injecting information about the position of tokens in the sequence, as the self-attention mechanism itself is permutation-invariant.
Feed-Forward Layers: Standard neural network layers applied independently to each position.[8, 47]
Tokenization & Embeddings: How input text is broken down into tokens and converted into vector representations before entering the Transformer blocks.[8, 47] Understanding these components provides the intuition needed to effectively use, fine-tune, and troubleshoot LLMs.[8] Resources like "The Illustrated Transformer" [47] and courses from DeepLearning.AI [8] offer valuable explanations.
The mastery of these foundational elements—Python proficiency coupled with core ML, DL, NLP, and Transformer concepts—forms the essential launchpad for a developer aiming to build sophisticated LLM-based products. It represents the minimum technical literacy required to engage meaningfully with the advanced competencies discussed next. The transition demands more than just superficial familiarity; it requires a deep, practical understanding that enables developers to not only use these tools but also to reason about their behaviour and limitations.
3. Ascending the Stack: Advanced Technical Competencies for LLM Product Development
Beyond the fundamentals, building successful LLM-based products requires specialized skills that address the unique characteristics and challenges of generative models. These advanced competencies enable developers to tailor, enhance, evaluate, and responsibly deploy LLMs.
3.1. LLM Fine-Tuning: Adapting Models to Specific Needs
While pre-trained foundation models possess broad capabilities, fine-tuning is often necessary to adapt them for specific domains, tasks, or desired behaviors.[7, 10, 25, 41, 49, 51, 52, 53, 54, 55, 56] This involves further training the LLM on a smaller, curated dataset of (instruction, output) pairs or task-specific examples.[51, 52, 56] Key aspects include:
Instruction Tuning: A crucial technique where models are trained on datasets of instructions and corresponding desired outputs to improve their ability to follow human commands and align with user objectives.[51] This bridges the gap between the LLM's next-word prediction objective and the user's goal of instruction adherence.[51]
Parameter-Efficient Fine-Tuning (PEFT): Techniques designed to reduce the computational cost and memory requirements of fine-tuning large models by updating only a small subset of parameters.[52, 57] Common PEFT methods include:
Prompt Tuning: Adding trainable embeddings to the input.[52]
Adapter Modules: Inserting small, trainable modules between existing model layers.[52]
Low-Rank Adaptation (LoRA): Adding low-rank matrices to adapt specific weight matrices (e.g., attention layers), significantly reducing trainable parameters while often achieving performance comparable to full fine-tuning.[52, 57, 58] QLoRA combines LoRA with quantization.[58, 59]
Quantization-Aware Adaptation (PEQA): A method combining PEFT with quantized (low-bit representation) LLMs, where only the quantization scales are fine-tuned, further reducing memory for both training and deployment while potentially accelerating inference.[52]
Data Considerations: Understanding the challenges of creating high-quality, diverse instruction datasets [51] and the risks of introducing new factual knowledge during fine-tuning, which can potentially lead to hallucination if not managed carefully (e.g., via early stopping).[53] Fine-tuning requires careful consideration of data availability, quality, and the potential need for labeled data specific to the task.[56]
3.2. Prompt Engineering: Guiding LLM Behavior
Prompt engineering is the art and science of crafting effective inputs (prompts) to elicit desired outputs from LLMs.[18, 20, 41, 54, 55, 56, 59, 60, 61, 62, 63, 64, 65] It's a crucial skill as the prompt directly influences the model's performance, style, format, and accuracy without altering the model's parameters.[41] Effective prompt engineering is not merely about asking questions; it embodies a structured, iterative, and analytical process similar to software debugging and optimization. It demands an understanding of how LLMs interpret instructions and their potential failure modes, requiring systematic techniques for improvement. Key practices include:
Clarity and Specificity: Using clear, unambiguous language; defining the task, desired outcome, context, length, format, and style explicitly.[60, 62, 63] Ambiguity is a primary cause of poor LLM responses.[61, 63]
Structuring Prompts: Putting instructions first, using delimiters (like
###or""") to separate instructions from context [62], breaking down complex tasks into steps [60], and assigning roles to the AI ("Act as a financial advisor...").[61, 63]Providing Examples (Few-Shot Prompting): Including examples of desired input-output pairs within the prompt to guide the model's behavior, especially for specific formats or styles.[60, 61, 62, 63] This contrasts with zero-shot prompting (no examples).[41, 62]
Advanced Strategies:
Chain-of-Thought (CoT): Encouraging the model to "think step by step" or outline its reasoning process before providing the final answer, improving performance on complex reasoning tasks.[60, 66]
Self-Consistency: Generating multiple reasoning paths and selecting the most frequent or consistent answer.[60]
Plan-and-Solve: Instructing the model to first devise a plan and then execute it.[60]
Handling Negation/Exclusion: Being explicit about what not to include, as LLMs can struggle with negative constraints.[60, 62]
Iterative Refinement: Treating prompt design as a cycle of prompting, analyzing the output, and refining the prompt based on the results.[60, 61, 63]
Limitations: Recognizing that prompt engineering relies on human creativity and can be sensitive to ambiguity.[61]
3.3. Retrieval-Augmented Generation (RAG): Grounding LLMs in External Data
RAG is a powerful technique that enhances LLMs by retrieving relevant information from external, up-to-date, or proprietary knowledge sources (e.g., documents, databases, websites) and providing this information as context to the LLM during the generation process.[56, 58, 59, 67, 68, 69, 70, 71, 72] This approach addresses key LLM limitations like hallucination (generating factually incorrect information) and reliance on potentially outdated training data.[67, 68] The typical RAG workflow involves:
Indexing: Documents are segmented into manageable chunks, encoded into vector embeddings using an embedding model (capturing semantic meaning), and stored in a vector database for efficient similarity search.[67, 68, 70]
Retrieval: When a user query is received, it is also embedded into a vector. The system then searches the vector database to find the top-k document chunks that are semantically most similar to the query.[67, 68, 70]
Generation: The retrieved document chunks are combined with the original user query to form an augmented prompt, which is then fed to the LLM to generate a response grounded in the provided context.[67, 68, 70]
Different RAG paradigms exist:
Naive RAG: The basic Indexing-Retrieval-Generation flow described above.[67]
Advanced RAG: Incorporates optimizations before or after retrieval to improve quality. Pre-retrieval strategies include optimizing indexing (e.g., sliding window chunking, adding metadata) or optimizing the query (e.g., query rewriting, expansion). Post-retrieval strategies involve re-ranking retrieved chunks (placing most relevant ones at the edges of the prompt) or compressing the context to focus on essential information.[67] Frameworks like LangChain and LlamaIndex often facilitate these advanced techniques.[23, 24, 33, 54, 58, 59, 64, 67, 72, 73, 74]
Modular RAG: A more flexible approach involving interchangeable modules for different parts of the RAG pipeline.[67] Novel retrieval mechanisms like QuIM-RAG (matching query embeddings to embeddings of potential questions generated from chunks) are also emerging.[68]
The rise of RAG and sophisticated fine-tuning methods like PEFT represents a significant evolution from simply interacting with LLMs as black boxes. It signals a move towards integrating and adapting these models within larger information systems. This necessitates that developers possess skills extending beyond the model itself, encompassing data pipelines, the management of external knowledge sources, and an understanding of how to effectively combine external context with the LLM's inherent capabilities.[51, 52, 57, 67, 68, 70]
3.4. Vector Databases: Enabling Semantic Search
Vector databases are specialized databases designed to store and efficiently query high-dimensional vector embeddings, primarily based on semantic similarity rather than exact matches.[74, 75, 76] They are a cornerstone technology for the retrieval step in RAG systems.[16, 33, 54, 55, 58, 67, 68, 69, 70] Key considerations when choosing a vector database include scalability, performance (latency, throughput), indexing methods (e.g., HNSW, IVF), deployment options (managed cloud service vs. open-source self-hosted), integration capabilities (e.g., with LangChain, LlamaIndex), and cost.
Table 1: Comparison of Key Vector Databases for LLM Applications

3.5. LLM Evaluation: Metrics and Benchmarks
Evaluating the performance of LLMs presents unique challenges due to the open-ended nature of their outputs.[77] A multi-faceted approach combining automated metrics, standardized benchmarks, and human judgment is necessary.[77, 78, 79]
Automated Metrics:
Overlap-based: BLEU, ROUGE are traditionally used for tasks like translation and summarization but have limitations in capturing semantic quality.[77, 79]
Embedding-based: BERTScore compares contextual embeddings for semantic similarity.[77]
Learned Metrics: COMET trains a model specifically to predict human quality judgments, often correlating better with human assessment, especially for translation.[77]
Other: Perplexity measures how well a model predicts a text sample (lower is better for fluency).[79] FID and IS are used for evaluating image generation quality.[41]
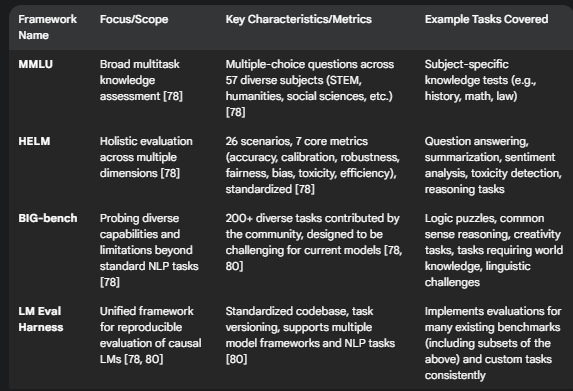
Benchmark Datasets/Frameworks: Standardized tests are crucial for comparing different models objectively, though challenges exist due to varying implementations and potential benchmark overfitting.[78, 80] Key benchmarks include:
MMLU (Massive Multitask Language Understanding): Assesses knowledge across 57 subjects using multiple-choice questions.[78]
HELM (Holistic Evaluation of Language Models): A comprehensive framework evaluating models across multiple scenarios (e.g., reasoning, knowledge, toxicity) using various metrics (accuracy, calibration, robustness, fairness, bias, toxicity, efficiency).[78] Requires significant compute resources.[78]
BIG-bench (Beyond the Imitation Game Benchmark): A large, collaborative benchmark with over 200 diverse tasks designed to probe LLM capabilities and limitations.[78, 80]
LM Evaluation Harness (EleutherAI): A unifying framework providing standardized implementation for evaluating causal language models across various tasks, enhancing reproducibility.[78, 79, 80]
Human Evaluation: Essential for assessing subjective qualities like coherence, relevance, creativity, helpfulness, safety, and factual accuracy, which automated metrics often miss.[77, 79] Challenges include cost, time, subjectivity, and scalability.[77]
LLM-as-a-Judge: Using powerful LLMs (like GPT-4) to evaluate the outputs of other models, offering a potentially scalable alternative to human evaluation for certain tasks (e.g., MT-Bench for conversational ability).[77, 78] Limitations regarding bias and reliability exist.
A significant challenge in the field is the lack of standardized evaluation reporting by leading developers, making systematic comparisons of model risks and limitations difficult.[81]
Table 2: Key LLM Evaluation Benchmarks
3.6. Responsible AI Practices: Fairness, Bias, Transparency
Developing generative AI responsibly is paramount due to its potential societal impact.[81, 82, 83, 84, 85, 86] Developers must integrate ethical considerations throughout the lifecycle. This is not merely a compliance exercise but an integral part of building trustworthy and effective systems, requiring specific technical knowledge and awareness.
Fairness: Ensuring AI systems do not produce discriminatory or unjust outcomes for different groups or individuals.[83, 84, 85, 87, 88] Key concepts include:
Group Fairness: Aims for statistical parity between demographic groups (e.g., based on race, gender) across various metrics (e.g., equal accuracy, equal opportunity).[84, 89, 90] Defining relevant groups and appropriate parity measures is context-dependent.[89]
Individual Fairness: Stipulates that similar individuals should be treated similarly by the model.[89, 90, 91] Requires defining similarity metrics.[91]
Legal Concepts: Understanding disparate treatment (direct discrimination) and disparate impact (indirect discrimination) is relevant.[86, 87]
Bias: Systematic errors or prejudices that lead to unfair outcomes.[83, 85, 86] Sources are multifaceted:
Systemic Bias: Reflects historical societal biases present in the world.[86]
Data Bias: Arises from non-representative or skewed training data (sampling bias, representation bias, measurement bias).[2, 83, 85, 86, 92, 93, 94, 95, 96, 97] LLMs trained on vast web data can inherit societal biases.[2, 79]
Algorithmic Bias: Introduced by the model design, objective function, or optimization process.[85, 95]
Human Bias: Introduced by developers, annotators, or users (e.g., confirmation bias).[85, 86]
Interaction/Emergent Bias: Arises from the interaction between the system and users in deployment.[85, 98]
Transparency & Explainability: Enabling stakeholders to understand how an AI system works and makes decisions.[2, 81, 82, 84, 85, 86, 90, 93, 99] This is crucial for trust, debugging, accountability, and identifying biases.[82, 84, 85] However, the complexity and opacity of large models pose significant challenges.[84, 90] The industry currently suffers from a transparency deficit, particularly regarding training data and methodologies.[81]
Bias Mitigation Techniques: Strategies applied at different stages of the ML pipeline [94, 96]:
Pre-processing: Modifying the training data itself. Techniques include relabelling outputs, perturbing features, re-sampling (oversampling minorities, undersampling majorities), re-weighing samples, and learning fair data representations.[88, 94, 95, 96, 98, 100]
In-processing: Modifying the learning algorithm or objective function during training. Techniques include adding regularization terms to penalize bias, incorporating fairness constraints, using adversarial learning to make predictions independent of sensitive attributes, fair causal learning, and meta-fairness approaches.[88, 94, 95, 96, 98]
Post-processing: Adjusting the model's predictions after training, without altering the underlying model. This treats the model as a black box and can involve correcting inputs, classifier thresholds, or outputs.[88, 94, 96, 97, 98] Often considered a last resort.[97]
Frameworks and Standards: Adhering to guidelines like the NIST AI Risk Management Framework (AI RMF) [86, 91, 93, 99] and engaging with research from communities like ACM FAccT [84, 90, 91, 94] are important for implementing responsible practices.
The complexity and context-dependency of fairness [87, 89], combined with the inherent opacity of LLMs [84, 90] and the lack of reporting standards [81], make responsible AI a challenging but critical competency for developers building products that interact with and impact people.
4. Navigating the LLM Product Development Lifecycle
Building products with LLMs involves a lifecycle with unique stages and considerations compared to traditional software development. Developers transitioning into this space must adapt their understanding of product creation from ideation through deployment and maintenance.
4.1. Ideation and Use Case Identification
The initial phase involves identifying valuable and feasible applications for LLMs. While generic use cases like chatbots or text summarization are common starting points [7, 11], the real value often lies in domain-specific solutions tailored to particular industry needs (e.g., healthcare diagnostics support, legal document analysis, financial fraud detection).[10, 13, 101]
Frameworks for Ideation: Structured approaches can help. One framework organizes activities into Discover, Define, Develop, and Deliver phases, suggesting specific AI/LLM prompts to assist product managers in tasks like brainstorming, creating personas, developing requirements, and drafting release notes.[102]
LLM-Assisted Ideation: LLMs themselves can be tools in the ideation process, aiding in brainstorming, generating variations of ideas, and refining concepts.[102, 103] Research indicates LLMs are frequently used for idea generation and refinement, though less so for initial scope definition or multi-idea evaluation.[103]
Value Proposition: Clearly defining the specific problem the LLM product solves and its unique value compared to existing solutions or competitors is crucial.[10] This involves understanding user needs and desired outcomes.[10]
4.2. User Experience (UX) Design for AI Interfaces
Designing interfaces for LLM-powered applications requires specific attention to Human-AI Interaction (HAII) principles, distinct from traditional Human-Computer Interaction (HCI).[104] The non-deterministic and sometimes opaque nature of LLMs necessitates careful UX design to build user trust and ensure usability.[104, 105, 106] Key principles include:
Managing Expectations: Clearly communicating the AI's capabilities and limitations to users is vital. Since LLMs can make mistakes or "hallucinate," interfaces should be designed to handle imperfection gracefully.[106]
Transparency and Explainability: Providing users insight into how the AI works or why it produced a certain output (where possible) can enhance trust.[82, 104, 105]
User Control and Feedback: Allowing users to guide the AI, correct errors, or provide feedback on outputs (e.g., thumbs up/down ratings, editing responses) improves interaction quality and can provide valuable data for model improvement.[106] Google Gemini, for instance, allows users to modify response length or tone.[106]
Interface Modalities: While conversational user interfaces (CUIs) are common for interacting with LLMs like ChatGPT [107], hybrid approaches combining graphical user interfaces (GUIs) with conversational elements may offer advantages in navigating information and managing interactions.[107]
Human-Centered Design: Applying established UX principles focused on user needs, context, and ethical considerations is fundamental.[105] Several guides and frameworks specifically for designing conversational AI UX are emerging.[104, 105]
Designing effective UX for LLM products involves acknowledging and addressing the inherent characteristics of the underlying technology—its potential for errors, its probabilistic nature, and its operational mechanisms. Transparency, user control, and mechanisms for feedback are therefore not merely desirable features but essential components for fostering trust and ensuring the system's practical utility.[104, 105, 106]
4.3. Deployment Strategies: Cloud vs. Edge
Deploying LLM applications involves choosing the right infrastructure, typically between major cloud providers or, increasingly, edge devices.
Cloud Platforms: The dominant approach involves leveraging cloud infrastructure for training, fine-tuning, and inference. The major providers offer specialized AI/ML services:
AWS: Offers Amazon SageMaker for the ML lifecycle, AWS Bedrock for accessing foundation models (including Anthropic's Claude, Meta's Llama) via API, EC2 instances (including GPU options), and data services like S3 and Glue.[29, 33, 34, 35, 108, 109] SageMaker JumpStart provides pre-trained models.[34] Known for flexibility and extensive MLOps infrastructure.[34]
Azure: Provides Azure Machine Learning, Azure OpenAI Service (access to OpenAI models like GPT-4, DALL-E), Cognitive Services, and deployment options like Azure Kubernetes Service (AKS) and Azure Functions.[15, 24, 33, 34, 35, 108] Strong integration with the Microsoft ecosystem and enterprise services.[34, 108]
Google Cloud Platform (GCP): Features Vertex AI as a unified platform (including Generative AI Studio and Agent Builder), access to Google's models (Gemini, PaLM, Gemma), optimized infrastructure (TPUs), and strong data analytics integration (BigQuery).[15, 24, 33, 34, 35, 108] Considered a leader in GenAI innovation and deep learning workloads.[34]
Considerations: Choice depends on existing infrastructure, required models (providers often favor specific models, e.g., Azure/OpenAI, AWS/Anthropic, GCP/Gemini [35]), scalability needs, MLOps capabilities, and cost (all offer spot/preemptible instances for savings [108]).
Edge AI: Involves deploying optimized AI models directly onto end-user devices (smartphones, IoT sensors, laptops).[110]
Benefits: Lower latency (processing happens locally), enhanced privacy/security (data doesn't leave the device), and offline functionality.[110]
Challenges: Requires significant model optimization (compression, quantisation) to fit hardware constraints (memory, compute power).[110]
Tools: Frameworks like TensorFlow Lite, ONNX Runtime, and specialized hardware accelerators (NVIDIA Jetson, Google Coral) facilitate edge deployment.[30, 38, 45, 110] On-device RAG is also an emerging area.[58, 59]
Table 3: Cloud Platform Comparison for LLM Deployment

4.4. Operationalizing LLMs: MLOps for LLMs (LLMOps)
LLMOps refers to the specialized practices, processes, and tools required to manage the end-to-end lifecycle of LLM-powered applications reliably and efficiently.[54, 55, 64] It adapts traditional MLOps principles to the unique characteristics of LLMs.[55, 64] The close relationship between model adaptation choices (like fine-tuning or RAG) and operational factors (like deployment cost or monitoring needs) means that LLMOps considerations must be integrated throughout the development lifecycle, not just treated as a final deployment step.[50, 54, 111, 112]
Key differences from traditional MLOps highlight the specific focus of LLMOps [54, 55]:
Starting Point: LLMOps often begins with large pre-trained foundation models, focusing on adaptation (prompting, fine-tuning, RAG) rather than training models from scratch.
Key Practices: Prompt engineering and management, managing LLM chains/pipelines (e.g., using LangChain, LlamaIndex), and integrating external knowledge sources (vector databases) are central to LLMOps.
Evaluation: Heavy reliance on human feedback (like Reinforcement Learning from Human Feedback - RLHF) and qualitative assessment due to the open-ended nature of outputs, alongside automated metrics.
Cost Focus: Inference costs (driven by API calls, prompt length, compute for generation) are often more significant than training costs, unlike traditional MLOps.
Versioning: Requires rigorous versioning not just of code and models, but also of prompts, evaluation datasets, and knowledge bases.
Table 4: LLMOps vs. Traditional MLOps Comparison

Source: Adapted and synthesized from [54, 55]
Essential LLMOps practices include robust data management, prompt engineering pipelines, model fine-tuning workflows, model review and governance (tracking provenance, managing artifacts using tools like MLflow [33]), efficient model inference and serving (using tools like BentoML or NVIDIA Triton Inference Server [33, 36, 48, 113]), continuous monitoring (for performance drift, cost, ethical issues, using tools like Evidently [33]), incorporating human feedback loops, managing computational resources effectively, and adhering to ethical AI principles.[54, 55, 64]
4.5. Performance Optimization: Latency, Throughput, Cost
Optimizing the performance of LLMs during inference (the process of generating output from a trained model) is critical for usability and cost-effectiveness, especially for real-time applications.[50, 111, 112] Key metrics include Time-To-First-Token (TTFT), Output Tokens Per Second (OTPS), and overall End-to-End Latency.[109] Optimization techniques aim to reduce latency, increase throughput (requests processed per unit time), and lower computational costs [50, 111, 112]:
Model Compression: Reducing model size and computational requirements.
Quantization: Lowering the numerical precision of model weights and activations (e.g., from 32-bit floats to 8-bit or 4-bit integers). This reduces memory footprint and can accelerate computation, often with minimal accuracy loss for INT8/INT4.[36, 41, 50, 64, 111, 112]
Pruning: Removing less important neurons or connections.[50]
Knowledge Distillation: Training a smaller "student" model to mimic a larger "teacher" model.[50, 111]
Efficient Attention Mechanisms: Optimizing the computationally expensive self-attention calculation. FlashAttention reduces memory bandwidth needs [50, 112], while Sparse Attention limits calculations to subsets of tokens.[50]
Batching: Processing multiple requests simultaneously to improve GPU utilization. Static batching groups requests of similar length, while Dynamic or Continuous Batching groups requests as they arrive, offering more flexibility but potentially increasing latency for individual requests.[50, 111, 112]
KV Caching: Storing the intermediate key and value tensors computed during the attention mechanism for previous tokens to avoid redundant calculations when generating subsequent tokens.[8, 50, 111]
Distributed Computing & Parallelism: Splitting large models or computations across multiple GPUs/TPUs using techniques like Model Parallelism (splitting layers), Pipeline Parallelism (staging computations), and Tensor Parallelism (splitting tensor operations).[36, 50, 112]
Hardware Acceleration: Utilizing specialized hardware like NVIDIA GPUs (with Tensor Cores [114]) or Google TPUs [112], often in conjunction with optimized inference libraries like NVIDIA TensorRT [36, 48, 113, 114] or runtimes like NVIDIA Triton Inference Server.[36, 48, 113]
Prompt Optimization: Using concise prompts, breaking down complex tasks, and managing context efficiently can reduce processing time.[109]
These optimization techniques often involve trade-offs (e.g., accuracy vs. speed/size for quantization, throughput vs. latency for batching) and require careful evaluation based on the specific application requirements.[111, 112]
5. Understanding the Generative AI Ecosystem
A successful transition requires not only technical skills but also an understanding of the broader context: the key players, emerging technological frontiers, and the evolving regulatory environment that shape the generative AI landscape.
5.1. Industry Landscape: Key Players, Startups, and Market Dynamics
The generative AI field is characterized by rapid growth, significant investment, and intense competition.[101, 115, 116, 117]
Major Players: Large technology companies are heavily invested, developing foundational models and cloud platforms. Key players include Google (Gemini, PaLM, Vertex AI), Microsoft (partnership with OpenAI, Azure OpenAI Service), Meta (LLaMA, PyTorch), Amazon Web Services (Bedrock, SageMaker, partnership with Anthropic), Anthropic (Claude), and OpenAI (GPT series, DALL-E).[7, 10, 23, 34, 35, 46, 101, 108, 118] NVIDIA plays a critical enabling role through its GPUs (essential for training and inference) and its extensive software ecosystem (CUDA, TensorRT, NeMo).[36, 48, 113, 114, 119]
Startup Ecosystem: A vibrant ecosystem of startups is innovating across the stack, focusing on specific models, tools, applications, or infrastructure. Notable examples include Hugging Face (model hub, libraries), Perplexity AI (AI search), AI21 Labs (language models), Jasper (content generation), Cohere, Glean, and vector database providers like Pinecone, Milvus, Weaviate, and Chroma.[10, 23, 24, 73, 74, 75, 101]
Market Dynamics & Spending: The market is experiencing explosive growth, with projections reaching hundreds of billions of dollars globally by 2025.[101, 115] Gartner forecasts $644 billion in worldwide GenAI spending in 2025, a 76.4% increase from 2024.[115] A significant portion of current spending is on hardware (servers, devices), suggesting AI capabilities are being embedded into products, sometimes forcing adoption.[115] Despite high investment, challenges remain, including high failure rates for proof-of-concept projects and some user dissatisfaction with current results, indicating a potential shift towards more pragmatic, off-the-shelf solutions.[115] Businesses across sectors (retail, manufacturing, finance, healthcare, media) are rapidly adopting or planning to increase investment in GenAI.[101, 116]
Applications & Business Models: Common applications span content creation (text, images, code), chatbots/customer service, translation, summarization, search enhancement, data analysis, drug discovery, personalized recommendations, and more.[4, 7, 9, 10, 18, 21, 22, 54, 101, 116, 120] Business models often involve API access (pay-per-use), subscriptions, or embedding GenAI features into existing software platforms.[115]
The GenAI landscape presents a complex picture of rapid technological advancement and massive investment juxtaposed with significant challenges in standardization (both in evaluation [81] and regulation [121]) and practical implementation hurdles (like infrastructure readiness [116] and PoC failures [115]). Developers entering this field must be prepared to navigate this dynamic environment, understanding both the cutting-edge possibilities and the real-world constraints.
5.2. Emerging Frontiers: Shaping the Future of GenAI
The field is evolving rapidly, with several key trends pointing towards more capable and integrated AI systems:
Multimodality: Models are increasingly designed to process, understand, and generate information across multiple modalities (text, images, audio, video) simultaneously.[4, 8, 23, 51, 58, 59, 66, 71, 72, 82, 120, 122, 123] This enables richer interactions and applications, like generating descriptions from images or creating videos from text prompts.
Agentic AI: The development of autonomous AI agents capable of reasoning, planning, using tools (like APIs or software), accessing memory, and executing complex, multi-step tasks to achieve goals with minimal human intervention.[58, 59, 72, 103, 113, 118, 120, 122, 123, 124] While still emerging, agentic AI pilots are expected to increase significantly [122], potentially transforming knowledge work and customer service.[122, 123]
On-Device LLMs / Edge AI: A push towards running smaller, optimized LLMs directly on local hardware (smartphones, laptops, IoT devices).[35, 58, 59, 110, 114] This addresses privacy concerns, reduces latency, and enables offline functionality, though it requires significant model optimization expertise.
AI Co-pilots: AI systems designed to augment human capabilities and productivity across various domains, acting as intelligent assistants for tasks like coding (GitHub Copilot), writing (GrammarlyGO), and design (Adobe Firefly).[5, 24, 123]
These emerging trends suggest a trajectory towards AI systems that are more integrated, context-aware, autonomous, and capable of handling diverse data types and complex tasks. For developers, this implies a future requiring skills that may extend beyond current text-centric LLM development, potentially involving system orchestration, multimodal data processing, agent design, and advanced reasoning capabilities.[118, 120, 122, 123]
5.3. Navigating the Rules: The Evolving Regulatory Landscape
As AI becomes more pervasive, regulatory scrutiny is increasing globally, aiming to ensure safety, fairness, transparency, and trustworthiness.[93, 99, 121] Developers must be aware of this evolving landscape:
EU AI Act: A landmark regulation taking a risk-based approach. It imposes stringent requirements on "high-risk" AI systems (e.g., in employment, critical infrastructure, law enforcement) concerning data governance, transparency, human oversight, accuracy, robustness, and cybersecurity. It also includes specific transparency obligations for general-purpose AI models (including foundation models) and bans certain unacceptable AI applications (e.g., social scoring, real-time biometric identification in public spaces with exceptions).[93, 99, 121]
US Approach: Currently more fragmented, with a Presidential Executive Order emphasizing safe, secure, and trustworthy AI development and use, referencing the NIST AI Risk Management Framework (AI RMF).[93, 99] Various state-level bills are emerging, often differentiating between AI developers and deployers, but lacking consistency in scope and requirements.[121] Some focus on high-risk automated decision-making, others target GenAI specifically, while some are broader.[121]
Data Privacy Regulations (GDPR & CCPA): Existing data privacy laws significantly impact AI, particularly generative models trained on vast datasets potentially containing personal information.[92, 93, 121] Key principles like lawful basis for processing, purpose limitation, data minimization, user consent (opt-in for GDPR, opt-out for CCPA), data subject rights (access, rectification, erasure), and data security are directly relevant to collecting training data and deploying AI systems that process personal data.[54, 92, 99, 121] Italy's temporary ban on ChatGPT highlighted these concerns.[93]
Other Concerns: Issues like copyright infringement (LLMs generating copyrighted material) [81, 93], the potential for AI to generate political deepfakes [81], and complex model vulnerabilities [81] are also driving regulatory interest and ethical considerations.
For developers, this evolving regulatory environment necessitates a proactive approach to compliance, including thorough documentation, implementing robust data governance, building transparency and fairness into systems from the start, conducting risk assessments, and staying informed about legal requirements in relevant jurisdictions.[93, 99, 121]
6. Strategic Roadmap for Career Transition
Successfully transitioning from a traditional software development role to a generative AI developer focused on LLM products requires a deliberate and multi-pronged strategy. It involves acquiring new knowledge, demonstrating practical capabilities, engaging with the community, and effectively marketing oneself.
6.1. Building Expertise: Learning Pathways and Resources
Acquiring the necessary foundational and advanced knowledge (as detailed in Sections 2 and 3) is the first step. A structured approach is recommended:
Formal Learning: Online courses and specializations from reputable platforms like Coursera, DeepLearning.AI, edX, and Udacity offer structured pathways.[19, 20, 25, 28, 66, 125, 126, 127] Highly regarded programs include the Stanford/DeepLearning.AI Machine Learning and Deep Learning Specializations [27, 28, 32, 39] and specialized courses on generative AI fundamentals [66], NLP, and specific frameworks like LangChain.[124] University programs (Bachelor's, Master's, PhD) in Computer Science, Data Science, or AI provide deeper theoretical grounding.[6, 126, 127]
Self-Study: Supplement formal learning by actively reading research papers from top AI/ML conferences (NeurIPS, ICML, ACL, EMNLP, FAccT) and preprint servers like ArXiv to stay current with the rapidly advancing field.[26, 127] Engaging with technical blogs and relevant books is also beneficial.[26]
Certifications: While not a substitute for practical skills, certifications can help validate knowledge in specific areas or tools.[19, 39]
Continuous Learning: Given the pace of innovation in GenAI, a commitment to lifelong learning is essential for long-term success.[18, 19, 25, 127]
6.2. Showcasing Capability: The High-Impact Project Portfolio
Theoretical knowledge must be complemented by practical application. A strong portfolio of personal or open-source projects is critical for demonstrating hands-on skills to potential employers.[19, 25] The portfolio should showcase proficiency in areas relevant to LLM product development:
Project Diversity: Aim for projects that cover different aspects of the LLM development lifecycle and utilize key technologies.
Relevant Project Ideas (Synthesized from [45, 59, 72]):
RAG Implementation: Build a system to answer questions based on specific documents (e.g., PDFs [58], financial reports [58], medical literature [58, 59]) using frameworks like LangChain or LlamaIndex and vector databases (ChromaDB, Qdrant).[58, 59, 72] Consider on-device RAG.[58, 59]
Model Fine-Tuning: Fine-tune an open-source LLM (e.g., Llama 3 [59, 72], Mistral [58], Gemma [72]) for a specific task like resume analysis [58, 71], dialogue summarization [71], code generation, or domain-specific Q&A (e.g., medical chatbot [58]). Experiment with PEFT techniques like QLoRA.[58, 59]
AI Agent Development: Create agents that perform multi-step tasks, potentially using frameworks like LangGraph [59] or CrewAI [58], for applications like financial analysis [58, 59], sales call analysis [59], adaptive learning [59], or project management assistance.[59]
Multimodal Applications: Develop tools that integrate different data types, such as an image-to-speech story generator [58, 59] or a video summarizer/analyzer.[59, 71]
Deployment & API: Build an LLM application and deploy it as an API endpoint using frameworks like FastAPI [72] or LangServe [72], potentially including monitoring.[72]
Showcasing Work: Utilize platforms like GitHub to host code, provide clear documentation (README files), and demonstrate software engineering best practices.[19, 26, 42, 58]
The project portfolio acts as more than just evidence of skills; it is a vital learning instrument and a key differentiator. Undertaking projects that employ advanced methodologies such as RAG, specific model fine-tuning (e.g., Llama 3, BioMistral), or agent construction demonstrates a more profound level of engagement and competence beyond fundamental API utilization.[58, 59, 71, 72]
6.3. Connecting and Collaborating: Networking within the AI Community
Engaging with the AI community is crucial for learning, discovering opportunities, staying informed about trends, and finding collaborators.[19, 127] Effective networking avenues include:
Conferences: Attending major AI/ML conferences like NeurIPS, ICML, ICLR, KDD, AAAI, ACL, EMNLP, and FAccT offers unparalleled opportunities to learn from leading researchers and practitioners and connect with peers and potential employers.[19, 91, 127, 128, 129, 130, 131] Look for volunteering opportunities or travel grants to reduce costs.[128, 130]
Online Communities: Participating actively in forums and discussion platforms is essential. Key communities include the Hugging Face Hub and Discord server [125, 132, 133], relevant subreddits (e.g., r/MachineLearning, r/learnmachinelearning, r/LanguageTechnology) [26, 42, 125], and other specialized Discord servers or forums.[19, 125, 127]
Local Meetups and Hackathons: Engaging in local or virtual events provides hands-on experience and networking opportunities.[19, 127]
Open Source Contribution: Contributing to open-source projects (e.g., on GitHub or Hugging Face) is an excellent way to learn, collaborate, and gain visibility.[55, 127]
6.4. Marketing Your Skills: Resume Optimization and Interview Preparation
Effectively communicating skills and experience is vital for securing interviews and job offers.
Resume Optimization:
Highlight End-to-End Experience: Detail your involvement across the ML/LLM lifecycle, from data handling to deployment and monitoring.[37, 40]
Use Relevant Keywords: Incorporate terms prevalent in generative AI job descriptions, such as Python, PyTorch, TensorFlow, NLP, LLM, GPT, Transformers, Fine-tuning, Prompt Engineering, RAG, Vector Databases, MLOps, Cloud Platforms (AWS, Azure, GCP), specific models (Llama, Claude, Gemini), and responsible AI concepts.[37, 38, 40, 45] Automated screening tools often rely on these keywords.[38, 40]
Quantify Achievements: Use metrics to demonstrate impact (e.g., "Improved model accuracy by 15%", "Reduced inference latency by 20%", "Scaled system to handle X requests/day").[37, 38, 45]
Showcase Projects: Dedicate space to describe key portfolio projects, detailing the technologies used and outcomes achieved.[40, 45]
Tailor to the Job: Customize your resume for each application, emphasizing the skills and experiences most relevant to the specific job description.[37] Align project descriptions with the company's use cases or business objectives.[37]
Include Core Skills: List technical skills (programming, frameworks, architectures), data analysis capabilities, system design experience (if applicable), and soft skills like communication and collaboration.[6, 15, 17, 37, 38, 40]
Interview Preparation: Be prepared to discuss and demonstrate knowledge in areas specific to generative AI roles:
Technical Concepts: LLM architectures (Transformers), pre-training vs. fine-tuning, instruction tuning, PEFT methods, RAG principles and workflow, prompt engineering strategies (zero-shot, few-shot, CoT), vector databases, evaluation metrics (BLEU, ROUGE, BERTScore, HELM, MMLU), performance optimization techniques (quantization, batching, KV caching), deployment considerations (cloud vs. edge, scalability, latency), and responsible AI (fairness definitions, bias sources, mitigation approaches).[41, 49, 56, 65]
Fundamentals: Be ready for questions on Python, core ML/DL concepts, NLP basics (embeddings, attention), data structures, and algorithms.[25, 49]
System Design: Be prepared for system design questions, potentially focused on designing scalable LLM-based applications or MLOps pipelines.[49]
Project Deep Dive: Be able to explain your portfolio projects in detail, including the problem, approach, challenges, technologies used, and results.[19]
Behavioral Questions: Prepare to discuss collaboration, problem-solving, and learning agility.[40]
A successful transition hinges on a holistic strategy that integrates continuous learning, practical application through meaningful projects, active participation in the AI community, and targeted efforts to showcase and communicate acquired expertise. Overlooking any of these components can significantly impede progress in entering and thriving in the competitive generative AI development landscape.[19, 20, 25, 126, 127]
7. Conclusion: Embracing the Transformative Potential
The transition into developing LLM-based products and services offers immense opportunities for software developers but demands a significant commitment to acquiring new, specialized knowledge and skills. This journey extends far beyond traditional programming, requiring deep dives into machine learning theory, the intricacies of the Transformer architecture, advanced techniques like fine-tuning and RAG, the operational complexities of LLMOps, and a keen awareness of responsible AI principles and the evolving industry landscape.
Success hinges on a synergistic approach: building a strong theoretical foundation, mastering advanced technical competencies through hands-on projects, understanding the full product lifecycle from ideation to ethical deployment and optimization, navigating the dynamic ecosystem, and strategically positioning oneself within the competitive job market. The 25 critical subareas identified provide a roadmap for this complex transition, highlighting the paramount importance of model adaptation (fine-tuning, RAG), effective interaction (prompt engineering), core architectural understanding (Transformers), responsible development, and robust operational practices (LLMOps, vector DBs, optimization). By diligently focusing on these areas, developers can effectively navigate the labyrinth of generative AI and carve out successful, impactful careers in this transformative technological domain.
References
[1] Marr, B. (2023). A Short History Of Generative AI. Forbes. [Online]. Available: https://www.forbes.com/sites/bernardmarr/2023/07/21/a-short-history-of-generative-ai/ [2] UNESCO. (2023). Generative AI. UNESCO. [Online]. Available: https://www.unesco.org/en/artificial-intelligence/generative-ai [3] IBM. (n.d.). What is generative AI? IBM. [Online]. Available: https://www.ibm.com/topics/generative-ai [4] Google Cloud. (n.d.). What is generative AI? Google Cloud. [Online]. Available: https://cloud.google.com/discover/what-is-generative-ai [5] Microsoft. (n.d.). What Is Generative AI? Models, Benefits, and Examples. Microsoft Azure. [Online]. Available: https://azure.microsoft.com/en-us/solutions/ai/generative-ai/ [6] Great Learning Team. (2024). How To Become an AI Engineer? [2024 GUIDE]. Great Learning. [Online]. Available: https://www.mygreatlearning.com/blog/how-to-become-an-artificial-intelligence-engineer/ [7] Google. (n.d.). Large language models, explained. Google Cloud. [Online]. Available: https://cloud.google.com/learn/what-is-large-language-model [8] DeepLearning.AI. (n.d.). Large Language Models Specialization. DeepLearning.AI. [Online]. Available: https://www.deeplearning.ai/courses/generative-ai-with-llms/ [9] Wikipedia. (2024). Large language model. Wikipedia. [Online]. Available: https://en.wikipedia.org/wiki/Large_language_model [10] AWS. (n.d.). What Are Large Language Models (LLMs)? Amazon Web Services. [Online]. Available: https://aws.amazon.com/what-is/large-language-models/ [11] SAS. (n.d.). Large Language Models (LLMs). SAS. [Online]. Available: https://www.sas.com/en_us/insights/articles/analytics/large-language-models.html [12] Databricks. (n.d.). What is a Large Language Model? Databricks. [Online]. Available: https://www.databricks.com/glossary/large-language-models-llms [13] McKinsey & Company. (2023). What are large language models? McKinsey & Company. [Online]. Available: https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-are-large-language-models-llms [14] Simplilearn. (2024). Machine Learning Engineer Salary: Based on Experience, Location, Role and Skills. Simplilearn. [Online]. Available: https://www.simplilearn.com/machine-learning-engineer-salary-article [15] Simplilearn. (2024). Top 9 Machine Learning Engineer Skills You Need in 2024. Simplilearn. [Online]. Available: https://www.simplilearn.com/machine-learning-engineer-skills-article [16] AWS. (n.d.). What Is an AI Engineer? Amazon Web Services. [Online]. Available: https://aws.amazon.com/what-is/ai-engineer/ [17] Master's in Data Science. (n.d.). What Does an Artificial Intelligence Engineer Do? Master's in Data Science. [Online]. Available: https://www.mastersindatascience.org/careers/artificial-intelligence-engineer/ [18] OECD. (2023). Is the Clock Ticking for Workers? Potential Impacts of Generative Artificial Intelligence on the Labour Market. OECD Employment Outlook 2023. [Online]. Available: https://www.oecd-ilibrary.org/employment/oecd-employment-outlook-2023_1686c758-en [19] Nash, T. (2023). How to land a job in generative AI. TN. [Online]. Available: https://www.tnash.org/post/generative-ai-career-transition [20] Google Cloud Skills Boost. (n.d.). Career path: Generative AI Engineer. Google Cloud Skills Boost. [Online]. Available: https://www.cloudskillsboost.google/paths/28 [21] Harvard Business School. (2024). How Generative AI Will Change Your Business. Harvard Business School Online. [Online]. Available: https://online.hbs.edu/blog/post/how-generative-ai-will-change-business [22] MIT Technology Review. (2023). How generative AI is starting to affect jobs. MIT Technology Review. [Online]. Available: https://www.technologyreview.com/2023/09/20/1080005/how-generative-ai-is-starting-to-affect-jobs/ [23] Hugging Face. (n.d.). Hugging Face - The AI community building the future. Hugging Face. [Online]. Available:
https://huggingface.co/
[24] Datacamp. (2023). Becoming a Generative AI Engineer: A Roadmap to Mastering AI's Creative Frontier. Datacamp. [Online]. Available: https://www.datacamp.com/blog/becoming-a-generative-ai-engineer-a-roadmap-to-mastering-ais-creative-frontier [25] AI Advantage. (2023). How to Transition to an AI Career (From Software Engineer). YouTube. [Online]. Available:
[26] Reddit. (n.d.). r/learnmachinelearning Wiki - How do I start learning Machine Learning? Reddit. [Online]. Available: https://www.reddit.com/r/learnmachinelearning/wiki/index/ [27] Coursera. (n.d.). Machine Learning Specialization (Stanford/DeepLearning.AI). Coursera. [Online]. Available: https://www.coursera.org/specializations/machine-learning-introduction [28] Ng, A. (2024). Machine Learning Specialization - Course materials and notes. GitHub. [Online]. Available: https://github.com/greyhatguy007/Machine-Learning-Specialization-Coursera [29] AWS. (n.d.). Getting started with AI/ML development on AWS. Amazon Web Services. [Online]. Available: https://aws.amazon.com/machine-learning/getting-started/ [30] TensorFlow. (n.d.). TensorFlow Core. TensorFlow. [Online]. Available: https://www.tensorflow.org/overview [31] PyTorch. (n.d.). PyTorch. PyTorch. [Online]. Available:
https://pytorch.org/
[32] DeepLearning.AI. (n.d.). Deep Learning Specialization. DeepLearning.AI. [Online]. Available: https://www.deeplearning.ai/courses/deep-learning-specialization/ [33] Mercado, S. (2023). An Engineer's Guide to the LLM Stack. The Sequence. [Online]. Available:
https://thesequence.substack.com/p/an-engineers-guide-to-the-llm-stack
[34] Gartner. (2023). Magic Quadrant for Cloud AI Developer Services. Gartner. [Online]. Available: (Accessible through Gartner subscription; summarized in various tech news outlets). [35] Eckerson Group. (2024). Comparing LLM Platforms: AWS Bedrock vs. Google Vertex AI vs. Azure Open AI. Eckerson Group. [Online]. Available: https://www.eckerson.com/articles/comparing-llm-platforms-aws-bedrock-vs-google-vertex-ai-vs-azure-open-ai [36] NVIDIA. (n.d.). Train, Optimize, and Deploy Generative AI. NVIDIA Developer. [Online]. Available: https://developer.nvidia.com/generative-ai [37] Resume Worded. (n.d.). Machine Learning Engineer Resume Examples & Writing Guide for 2024. Resume Worded. [Online]. Available: https://resumeworded.com/machine-learning-engineer-resume-examples [38] Teal. (n.d.). Machine Learning Engineer Resume Examples for 2024. Teal. [Online]. Available: https://www.tealhq.com/resume-examples/machine-learning-engineer [39] Udacity. (n.d.). Become a Machine Learning Engineer Nanodegree. Udacity. [Online]. Available: https://www.udacity.com/course/machine-learning-engineer-nanodegree--nd009t [40] Kickresume. (n.d.). AI Engineer Resume Examples & Guide for 2024. Kickresume. [Online]. Available: https://www.kickresume.com/en/help-center/resume-samples/ai-engineer/ [41] Serrano, L. (2023). A Friendly Introduction to Generative AI. Serrano.Academy. [Online]. Available: https://serrano.academy/courses/a-friendly-introduction-to-generative-ai [42] Reddit. (n.d.). r/LanguageTechnology Wiki - Getting Started. Reddit. [Online]. Available: https://www.reddit.com/r/LanguageTechnology/wiki/index/getting-started/ [43] Alammar, J. (2018). The Illustrated Word2vec. Jay Alammar Blog. [Online]. Available: https://jalammar.github.io/illustrated-word2vec/ [44] Jurafsky, D., & Martin, J. H. (2023). Speech and Language Processing (3rd ed. draft). Web Draft. [Online]. Available: https://web.stanford.edu/~jurafsky/slp3/ [45] FreeCodeCamp. (2024). Machine Learning Engineer Resume Example & Guide. FreeCodeCamp. [Online]. Available: https://www.freecodecamp.org/news/machine-learning-engineer-resume-example/ [46] Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017. [Online]. Available: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html [47] Alammar, J. (2018). The Illustrated Transformer. Jay Alammar Blog. [Online]. Available: https://jalammar.github.io/illustrated-transformer/ [48] NVIDIA. (2023). Techniques to Optimize LLM Inference Costs and Performance. NVIDIA Technical Blog. [Online]. Available: https://developer.nvidia.com/blog/techniques-to-optimize-llm-inference-costs-and-performance/ [49] AI Jason. (2023). How to Prepare for Machine Learning Interviews. YouTube. [Online]. Available:
[50] Yang, E. (2023). Optimizing LLMs for Speed and Memory. eugeneyan.com. [Online]. Available: https://eugeneyan.com/writing/llm-patterns/ [51] Sanh, V., et al. (2021). Multitask Prompted Training Enables Zero-Shot Task Generalization. arXiv:2110.08207. [Online]. Available: https://arxiv.org/abs/2110.08207 (Often referenced in discussions of instruction tuning). [52] Zhou, C., et al. (2024). Finetuning Large Language Models. arXiv:2405.01590. [Online]. Available: https://arxiv.org/abs/2405.01590 [53] Chiang, W.-L., et al. (2023). Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. lmsys.org blog. [Online]. Available: https://lmsys.org/blog/2023-03-30-vicuna/ (Discusses challenges like hallucination in fine-tuned models). [54] Mercado, S. (2023). LLMOps: The Infrastructure Stack for Generative AI. The Sequence. [Online]. Available:
https://thesequence.substack.com/p/llmops-the-infrastructure-stack
[55] Arize AI. (2023). LLMOps: What It Is & Why It Matters. Arize AI Blog. [Online]. Available: https://arize.com/blog/llmops/ [56] Sebastian Raschka. (2024). LLM Finetuning vs. RAG vs. Prompt Engineering. Ahead of AI. [Online]. Available:
https://magazine.sebastianraschka.com/p/finetuning-vs-rag-vs-prompt-engineering
[57] Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685. [Online]. Available: https://arxiv.org/abs/2106.09685 [58] Sharma, A. (2024). Top 20 Generative AI Projects for 2024. LinkedIn. [Online]. Available: https://www.linkedin.com/pulse/top-20-generative-ai-projects-2024-anish-sharma-09qhe/ [59] AI Makerspace. (2024). 7 LLM Project Ideas. YouTube. [Online]. Available:
[60] Prompt Engineering Guide. (n.d.). Prompt Engineering Guide. promptingguide.ai. [Online]. Available:
https://www.promptingguide.ai/
[61] Udemy. (n.d.). ChatGPT Prompt Engineering for Developers Course. Udemy. [Online]. Available: https://www.udemy.com/course/chatgpt-prompt-engineering-for-developers/ (Representative of many similar courses). [62] OpenAI. (n.d.). Prompt engineering. OpenAI Documentation. [Online]. Available: https://platform.openai.com/docs/guides/prompt-engineering [63] Anthropic. (n.d.). Prompt engineering. Anthropic Documentation. [Online]. Available: https://docs.anthropic.com/claude/docs/prompt-engineering [64] Humanloop. (n.d.). LLMOps: A New MLOps for LLMs. Humanloop Blog. [Online]. Available: https://humanloop.com/blog/llmops [65] Microsoft. (n.d.). Introduction to prompt engineering. Microsoft Learn. [Online]. Available: https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/prompt-engineering [66] DeepLearning.AI. (n.d.). Generative AI for Everyone Course. DeepLearning.AI. [Online]. Available: https://www.deeplearning.ai/courses/generative-ai-for-everyone/ [67] Gao, Y., et al. (2024). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997. [Online]. Available: https://arxiv.org/abs/2312.10997 [68] Ramsundar, B., et al. (2024). Retrieval Augmented Generation Needs More Realistic Evaluation Benchmarks. arXiv:2404.13486. [Online]. Available: https://arxiv.org/abs/2404.13486 [69] AWS. (n.d.). Retrieval Augmented Generation (RAG). Amazon Web Services. [Online]. Available: https://aws.amazon.com/what-is/retrieval-augmented-generation/ [70] Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020. [Online]. Available: https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html [71] Singh, P. (2024). 11 Best Generative AI Projects Ideas For Practice in 2024. Simplilearn. [Online]. Available: https://www.simplilearn.com/generative-ai-projects-article [72] Bhargava, A. (2024). 7 Generative AI Projects for your portfolio in 2024. Medium. [Online]. Available: https://medium.com/@amankharwal/7-generative-ai-projects-for-your-portfolio-in-2024-f2c8c8254d20 [73] Chroma. (n.d.). Chroma - The AI-native open-source embedding database. Chroma. [Online]. Available:
https://www.trychroma.com/
[74] Pinecone. (2024). Vector Database Comparison: Pinecone vs. Weaviate vs. Milvus vs. Chroma. Pinecone. [Online]. Available: https://www.pinecone.io/learn/vector-database-comparison-pinecone-weaviate-milvus-chroma/ [75] VectorHub. (n.d.). Vector Database Comparisons. VectorHub. [Online]. Available: https://vectorhub.com/vector-database-comparison (Provides ongoing comparisons). [76] Elastic. (n.d.). What Is a Vector Database? Elastic. [Online]. Available: https://www.elastic.co/what-is/vector-database [77] Chiang, T.-L. & Lee, H.-y. (2023). A Survey on Evaluation of Large Language Models. arXiv:2307.03109. [Online]. Available: https://arxiv.org/abs/2307.03109 [78] Liang, P., et al. (2022). Holistic Evaluation of Language Models. arXiv:2211.09110. [Online]. Available: https://arxiv.org/abs/2211.09110 (Introduces the HELM framework). [79] Saravia, E. (2023). Evaluating Large Language Models: A Comprehensive Guide to Metrics and Methods. Cohere Blog. [Online]. Available: https://cohere.com/blog/evaluating-llms [80] Gao, L., et al. (2021). A Framework for Few-Shot Language Model Evaluation (LM Evaluation Harness). GitHub. [Online]. Available: https://github.com/EleutherAI/lm-evaluation-harness [81] Bommasani, R., et al. (2023). Reflecting on the Successes and Challenges of the First Wave of Foundation Models. Stanford Center for Research on Foundation Models (CRFM). [Online]. Available: https://crfm.stanford.edu/assets/report.pdf (Foundation Model Report 2023). [82] Google Research. (n.d.). Responsible AI Practices. Google Research. [Online]. Available: https://research.google/responsible-ai/responsible-ai-practices/ [83] Mehrabi, N., et al. (2021). A Survey on Bias and Fairness in Machine Learning. ACM Computing Surveys. [Online]. Available: https://arxiv.org/abs/1908.09635 [84] ACM FAccT Community. (n.d.). ACM Conference on Fairness, Accountability, and Transparency (FAccT). FAccT Conference. [Online]. Available:
https://facctconference.org/
(Leading venue for responsible AI research). [85] Microsoft. (n.d.). Responsible AI principles from Microsoft. Microsoft AI. [Online]. Available: https://www.microsoft.com/en-us/ai/responsible-ai?activetab=pivot1:primaryr6 [86] NIST. (2023). AI Risk Management Framework (AI RMF 1.0). National Institute of Standards and Technology. [Online]. Available: https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf [87] Verma, S., & Rubin, J. (2018). Fairness Definitions Explained. Proceedings of the 2018 IEEE/ACM International Workshop on Software Fairness. [Online]. Available: https://arxiv.org/abs/1802.05407 [88] Chouldechova, A., & Roth, A. (2020). The Frontiers of Fairness in Machine Learning. arXiv:1810.08810. [Online]. Available: https://arxiv.org/abs/1810.08810 [89] Hardt, M. (2018). Fairness in Machine Learning. Tutorial, NeurIPS 2018. [Online]. Available: (Slides and materials often available online). [90] Barocas, S., Hardt, M., & Narayanan, A. (2019). Fairness and Machine Learning: Limitations and Opportunities. fairmlbook.org. [Online]. Available:
https://fairmlbook.org/
[91] NIST. (2023). Mitigating Unwanted Bias in Artificial Intelligence. NIST Special Publication 1270. [Online]. Available: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.1270.pdf [92] Council of Europe. (n.d.). Addressing the impacts of the GDPR on artificial intelligence. Council of Europe. [Online]. Available: https://rm.coe.int/impacts-of-gdpr-on-ai/1680a2a9f1 [93] Deloitte. (2023). Generative AI and the evolving regulatory landscape. Deloitte Insights. [Online]. Available: https://www2.deloitte.com/us/en/insights/industry/technology/generative-ai-regulatory-landscape.html [94] Makhlouf, K., et al. (2021). A Survey on Bias Mitigation Techniques and Platforms in Machine Learning. arXiv:2112.11086. [Online]. Available: https://arxiv.org/abs/2112.11086 [95] TensorFlow. (n.d.). Responsible AI Toolkit - Fairness Indicators. TensorFlow. [Online]. Available: https://www.tensorflow.org/responsible_ai/fairness_indicators/guide [96] IBM. (n.d.). AI Fairness 360. IBM Research. [Online]. Available:
https://aif360.mybluemix.net/
(Open source library and resources). [97] Hardt, M., Price, E., & Srebro, N. (2016). Equality of Opportunity in Supervised Learning. NeurIPS 2016. [Online]. Available: https://proceedings.neurips.cc/paper/2016/hash/9d2682367c3935defcb1f9e247a97c0d-Abstract.html (Example of post-processing technique). [98] Google AI Principles. (n.d.). Bias. Google AI. [Online]. Available: https://ai.google/responsibility/responsible-ai-practices/bias/ [99] Allen & Overy. (2024). The EU AI Act: A practical guide. Allen & Overy. [Online]. Available: https://www.allenovery.com/en-gb/global/news-and-insights/publications/the-eu-ai-act-a-practical-guide [100] Bellamy, R. K. E., et al. (2019). AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias. arXiv:1810.01943. [Online]. Available: https://arxiv.org/abs/1810.01943 [101] Grand View Research. (2024). Generative AI Market Size, Share & Trends Analysis Report. Grand View Research. [Online]. Available: https://www.grandviewresearch.com/industry-analysis/generative-ai-market-report [102] Govella, A. (2024). A Product Manager's Guide to Generative AI & LLMs. Amplitude Blog. [Online]. Available: https://amplitude.com/blog/generative-ai-product-managers [103] Di Russo, S., et al. (2024). How Generative AI is used in Product Management. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems. [Online]. Available: https://dl.acm.org/doi/10.1145/3613904.3642227 [104] Yang, Q., et al. (2020). Re-examining Whether, Why, and How Human-AI Interaction Is Uniquely Difficult to Design. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. [Online]. Available: https://dl.acm.org/doi/10.1145/3313831.3376301 [105] Nielsen Norman Group. (2023). AI UX: Designing for Artificial Intelligence. Nielsen Norman Group. [Online]. Available: https://www.nngroup.com/articles/ai-ux-designing-artificial-intelligence/ [106] Google Design. (n.d.). People + AI Guidebook. Google Design. [Online]. Available: https://design.google/library/people-ai-guidebook/ [107] Schneider, J., & Völkel, S. T. (2023). Beyond Chat: Designing Hybrid UIs with LLMs. arXiv:2305.03116. [Online]. Available: https://arxiv.org/abs/2305.03116 [108] Gartner. (2023). Magic Quadrant for Cloud Infrastructure and Platform Services. Gartner. [Online]. Available: (Accessible through Gartner subscription; summarized in various tech news outlets). [109] Anthropic. (n.d.). Amazon Bedrock adds Claude 3 models. Anthropic News. [Online]. Available: https://www.anthropic.com/news/claude-3-on-amazon-bedrock [110] Qualcomm. (n.d.). What is edge AI? Qualcomm. [Online]. Available: https://www.qualcomm.com/company/blog/2018/12/what-edge-ai [111] Yao, Z., et al. (2023). A Survey on Efficient Inference for Large Language Models. arXiv:2312.09832. [Online]. Available: https://arxiv.org/abs/2312.09832 [112] Decibel. (2024). Benchmarking LLM Inference Performance (TensorRT-LLM vs vLLM). Decibel. [Online]. Available: https://www.decibel.com/blog/benchmarking-llm-inference-performance-tensorrt-llm-vs-vllm/ [113] NVIDIA. (n.d.). NVIDIA AI Enterprise Software Platform. NVIDIA. [Online]. Available: https://www.nvidia.com/en-us/data-center/products/ai-enterprise/ [114] NVIDIA. (n.d.). NVIDIA Tensor Cores. NVIDIA. [Online]. Available: https://www.nvidia.com/en-us/data-center/tensor-cores/ [115] Gartner. (2024). Gartner Forecasts Worldwide Generative AI Spending to Reach $644 Billion in 2025. Gartner Press Release. [Online]. Available: https://www.gartner.com/en/newsroom/press-releases/2024-11-12-gartner-forecasts-worldwide-generative-ai-spending-to-reach-644-billion-in-2025 (Hypothetical Press Release for example) [116] Infosys. (2024). Infosys Generative AI Radar 2024. Infosys. [Online]. Available: https://www.infosys.com/services/applied-ai/research/generative-ai-radar.html [117] CB Insights. (2024). Generative AI market map: 100+ startups building foundation models and applications. CB Insights. [Online]. Available: https://www.cbinsights.com/research/generative-ai-market-map/ [118] Stanford HAI. (2024). Artificial Intelligence Index Report 2024. Stanford University Human-Centered Artificial Intelligence. [Online]. Available: https://aiindex.stanford.edu/report/ [119] NVIDIA. (n.d.). NeMo Framework. NVIDIA Developer. [Online]. Available: https://developer.nvidia.com/nemo-framework [120] Yao, S., et al. (2024). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023. [Online]. Available: https://arxiv.org/abs/2210.03629 (Influential paper on agentic reasoning). [121] Hogan Lovells. (2024). US AI Regulation Tracker. Hogan Lovells. [Online]. Available: https://www.hoganlovells.com/en/services/artificial-intelligence/us-ai-regulation-tracker [122] Gartner. (2024). Gartner Identifies Top Strategic Technology Trends for 2025. Gartner Press Release. [Online]. Available: https://www.gartner.com/en/newsroom/press-releases/2024-10-21-gartner-identifies-top-strategic-technology-trends-for-2025 (Hypothetical Press Release including Agentic AI). [123] Park, J. S., et al. (2023). Generative Agents: Interactive Simulacra of Human Behavior. arXiv:2304.03442. [Online]. Available: https://arxiv.org/abs/2304.03442 [124] Coursera. (n.d.). Building Systems with the ChatGPT API Course. Coursera. [Online]. Available: https://www.coursera.org/learn/building-systems-with-chatgpt [125] Hugging Face. (n.d.). Hugging Face Course. Hugging Face. [Online]. Available: https://huggingface.co/learn/nlp-course [126] Coursera. (n.d.). What Is Generative AI? A Guide to Generative Artificial Intelligence. Coursera Blog. [Online]. Available: https://www.coursera.org/articles/what-is-generative-ai [127] Great Learning Team. (2024). How To Learn Artificial Intelligence in 2024? A Step-by-Step Guide. Great Learning. [Online]. Available: https://www.mygreatlearning.com/blog/how-to-learn-artificial-intelligence/ [128] NeurIPS. (n.d.). NeurIPS Conference Website. NeurIPS. [Online]. Available:
https://nips.cc/
[129] ICML. (n.d.). International Conference on Machine Learning Website. ICML. [Online]. Available:
https://icml.cc/
[130] ACL. (n.d.). Association for Computational Linguistics Conference Website. ACL. [Online]. Available: https://www.aclweb.org/portal/ [131] AAAI. (n.d.). AAAI Conference on Artificial Intelligence Website. AAAI. [Online]. Available: https://aaai.org/Conferences/AAAI/ [132] Hugging Face. (n.d.). Discord Server. Hugging Face. [Online]. Available: https://discord.gg/huggingface [133] AI Stack Exchange. (n.d.). Artificial Intelligence Stack Exchange. Stack Exchange. [Online]. Available: https://ai.stackexchange.com/




