

LlamaIndex: Core Concepts & Getting Started
Tested with LlamaIndex v0.10.0 — Requires Python 3.8+

Imagine you’re a developer drowning in a sea of unorganised data, scattered across local files, remote APIs, and countless web pages.
Imagine a brilliant librarian who not only organises this chaos but also retrieves exactly what you need in moments.
This is the power of LlamaIndex. In this comprehensive guide, I’ll share my journey with LlamaIndex—a tool that has revolutionised my approach to building large language model (LLM) applications.
We’ll explore its inner workings, advanced best practices, and real-world integrations that make your development process smoother and more powerful. Let’s dive in and discover how LlamaIndex can transform your projects!
LlamaIndex, Core Concepts, Getting Started, Tutorial, Guide, Indexing, Data Indexing, LLMs, Language Models, Vector Index, Query Engine
What is LlamaIndex, and why?
The Problem LlamaIndex Solves
Without a structured system, managing diverse data sources for LLM applications is like navigating a labyrinth in the dark.
Data remains fragmented, and your LLM struggles to understand context, leading to inaccurate responses.
LlamaIndex resolves these challenges by efficiently organising your data into structured indexes, enabling fast, accurate retrieval and powerful query capabilities.
Key Benefits of LlamaIndex
Data connectivity seamlessly integrates with files, APIs, and web sources.
Efficient Data Structuring: Organises data into intuitive indexes, ensuring every piece finds its rightful place.
Powerful Querying: Supports rapid, context-rich searches to bolster high-quality LLM outputs.
Real-World Impact: Empowers applications ranging from semantic search engines to intelligent chatbots.
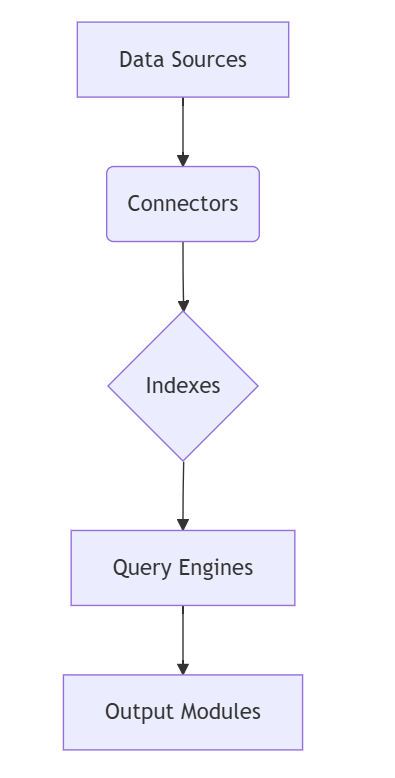
LlamaIndex’s Core Components
Understanding LlamaIndex starts with its building blocks. Each component—from data connectors to query engines—plays a crucial role in converting raw data into actionable insights.
Data Connectors
Data connectors are the entry points for your information. They fetch content from diverse sources, ensuring a reliable flow into LlamaIndex.
File Connectors, API Connectors, and Ethical Web Scraping
File connectors let you easily import local data, while API connectors and web scrapers extend your reach. For instance, here’s a robust API example using a real-world weather API with error handling:
import requests
from llama_index.core import APIDataConnector
try:
response = requests.get(
"https://api.openweathermap.org/data/2.5/weather?q=London&appid=YOUR_API_KEY",
timeout=10
)
response.raise_for_status()
weather_data = response.json()
api_connector = APIDataConnector(data=weather_data)
print("Weather Data Loaded:", api_connector.load_data())
except requests.exceptions.RequestException as e:
print("Error fetching API data:", e)And for ethical web scraping, always respect the site’s robots.txt:
import requests
from bs4 import BeautifulSoup
from llama_index.core import WebDataConnector
url = "https://example.com/data"
headers = {"User-Agent": "Mozilla/5.0"}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
web_data = soup.get_text()
web_connector = WebDataConnector(data=web_data)
print("Web Data Loaded:", web_connector.load_data())
except requests.exceptions.RequestException as e:
print("Error fetching web data:", e)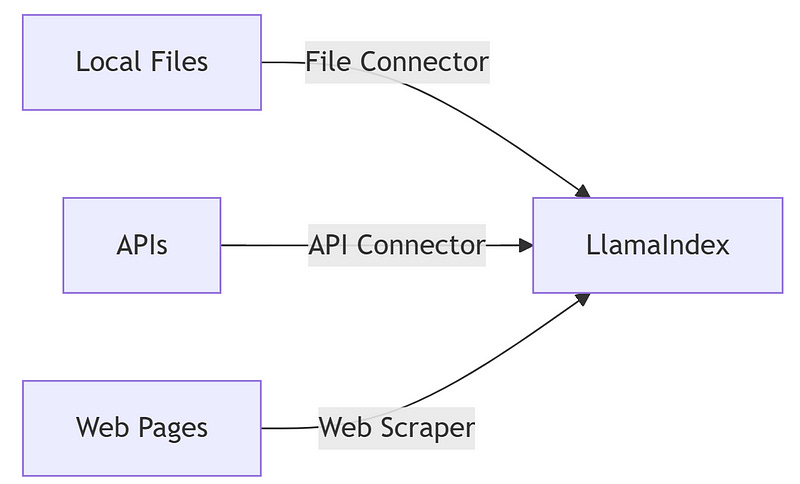
Data Structures (Indexes)
Indexes are the backbone of LlamaIndex. They organise your data for rapid and accurate retrieval. Let’s examine both basic and advanced index types.
ListIndex and VectorStoreIndex
ListIndex: Ideal for simple, sequential datasets.
VectorStoreIndex: Uses vector representations for similarity-based searches.
Example with VectorStoreIndex:
from llama_index.core import VectorStoreIndex
documents = ["Doc 1 content", "Doc 2 content", "Doc 3 content"]
vector_index = VectorStoreIndex.from_documents(documents, chunk_size=512) # Adjust chunk_size based on token limits
print("VectorStoreIndex created with", len(documents), "documents")TreeIndex, KeywordTableIndex, and ComposableIndex
TreeIndex: Organises data hierarchically, great for nested or structured content.
KeywordTableIndex: Indexes based on keywords for precise, targeted searches.
ComposableIndex: Combines multiple indexing methods for a hybrid approach.
Example:
from llama_index.core import TreeIndex, KeywordTableIndex, ComposableIndex
tree_index = TreeIndex.from_documents(["Section 1", "Section 2", "Section 3"])
keyword_index = KeywordTableIndex.from_documents(["Keyword A", "Keyword B"])
composable_index = ComposableIndex(indexes=[tree_index, keyword_index])
print("ComposableIndex created with", len(composable_index.indexes), "sub-indexes")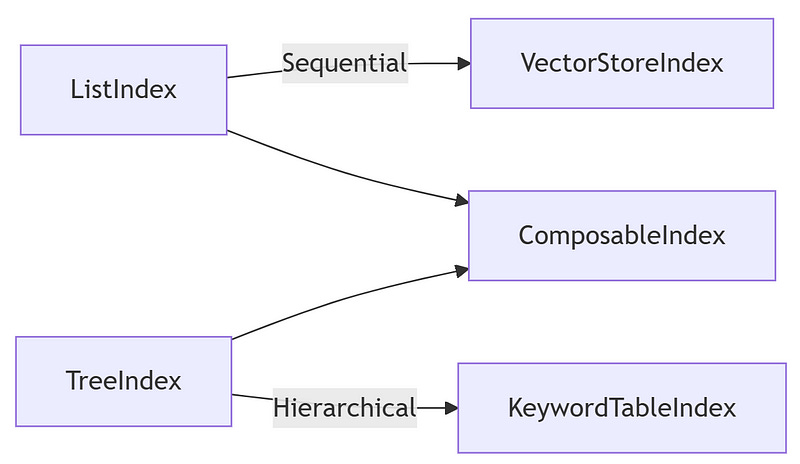
Query Engines
Query engines extract insights from your organized data. They employ various strategies — from basic keyword search to advanced hybrid methods that combine vector and keyword approaches.
Simple, VectorStore, and Advanced Query Engines
SimpleIndexQueryEngine: For straightforward queries.
VectorStoreQueryEngine leverages vector similarity to produce context-aware results.
Advanced query engines: Use a hybrid approach, integrating multiple search strategies for enhanced accuracy.
Example:
from llama_index.core import VectorStoreIndex, SimpleIndexQueryEngine
index = VectorStoreIndex.from_documents(documents, chunk_size=512)
query_engine = SimpleIndexQueryEngine(index=index)
try:
result = query_engine.query("Summarize the content of the document.")
print("Query Result:", result)
except Exception as e:
print("Error during query execution:", e)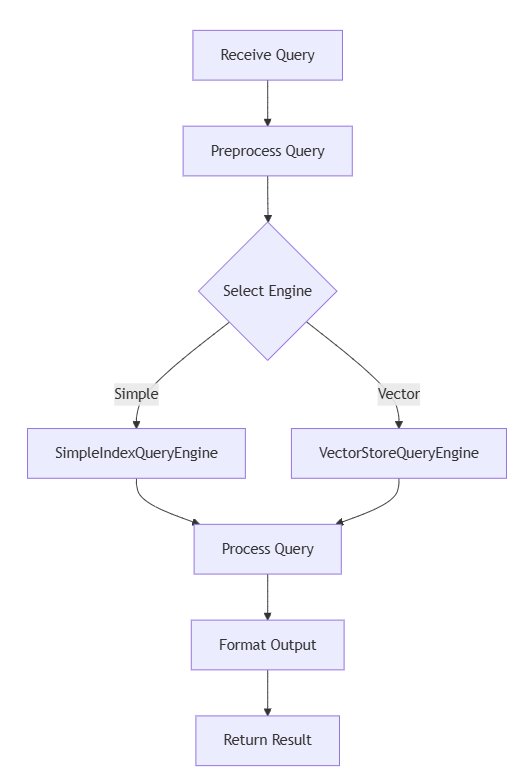
Output Modules
Output modules format the final query results. They range from simple response synthesizers that clean and present text to custom formatters that tailor outputs for specific applications.
Deep Dive: LLM Integration and Interaction
LLMs need well-organized, context-rich data to generate quality responses. LlamaIndex bridges this gap by preparing and tailoring the input context.
Managing Token Limits and Context Window Sizes
LLMs have token limits. LlamaIndex allows you to set chunk sizes (e.g., 512 tokens) to ensure the context fits within the LLM’s window. This avoids truncation and ensures completeness.
Customizing Prompts for Better Responses
Tailoring your prompts can improve response quality. For example, you might build a custom prompt that incorporates retrieved context:
# Example for customizing a prompt using retrieved-context
retrieved_context = "Extracted key points from the document..."
custom_prompt = f"Based on the following data:\n{retrieved_context}\nPlease summarize the main ideas."Best Practices in Application Development
Building robust LlamaIndex applications goes beyond coding—it requires good design, testing, and security practices.
Structuring Your LlamaIndex Application
Organize your project into modular components.
Configuration Management: Use configuration files or environment variables for settings (e.g., API keys, chunk sizes).
Separation of Concerns: Keep data ingestion, indexing, and querying in separate modules for clarity and maintainability.
Testing and Debugging
Implement both unit tests and integration tests.
Logging: Use Python’s logging module (e.g.,
logging.basicConfig(level=logging.INFO)) to trace operations.Debugging Tips: Check for common pitfalls such as token truncation and data format issues.
Deployment Considerations and Security Best Practices
Deployment Options: Consider containerization (Docker) or serverless functions for scalability.
Security Measures: Protect API keys with environment variables, sanitize user inputs, and validate queries to prevent injection attacks.
Performance Optimization
Optimizing performance is crucial for handling large datasets.
Benchmarking: Use profiling tools to measure indexing speed and query performance.
Memory Management: Adjust chunk sizes and index configurations to minimize memory usage.
Index Tuning: Experiment with different index types to find the optimal configuration for your use case.
Your First LlamaIndex Program: A Hands-On Tutorial
Let’s build a practical Q&A system that brings together all these concepts.
Environment Setup and Requirements
Set Up a Virtual Environment:
python3 -m venv llamaenv
source llamaenv/bin/activate # For Windows: llamaenv\Scripts\activateCreate a requirements.txt file:
llama-index-core
requests
beautifulsoup4
python-dotenv
openaiInstall Dependencies:
pip install -r requirements.txtPython Version: Ensure you are using Python 3.8 or higher.
Building the Application Step-by-Step
Loading Data from Files and APIs
from llama_index.core import FileDataConnector
# Load data from a file
try:
file_connector = FileDataConnector(file_path="data/sample.txt")
file_data = file_connector.load_data()
print("File Data Loaded:", file_data)
except Exception as e:
print("Error loading file data:", e)
import requests
from llama_index.core import APIDataConnector
# Load data from a weather API
try:
api_response = requests.get(
"https://api.openweathermap.org/data/2.5/weather?q=New+York&appid=YOUR_API_KEY",
timeout=10
)
api_response.raise_for_status()
api_data = api_response.json()
api_connector = APIDataConnector(data=api_data)
print("API Data Loaded:", api_connector.load_data())
except requests.exceptions.RequestException as e:
print("Error fetching API data:", e)Creating and Combining Indexes
from llama_index.core import ListIndex, TreeIndex, ComposableIndex
# Create a ListIndex from file data
list_index = ListIndex.from_documents(file_data)
# Create a hierarchical TreeIndex from structured sections
tree_index = TreeIndex.from_documents(["Section 1", "Section 2", "Section 3"])
# Combine indexes to leverage both sequential and hierarchical data retrieval
composable_index = ComposableIndex(indexes=[list_index, tree_index])
print("ComposableIndex created with", len(composable_index.indexes), "sub-indexes")Querying and Displaying Results
from llama_index.core import VectorStoreIndex, SimpleIndexQueryEngine
index = VectorStoreIndex.from_documents(file_data, chunk_size=512)
query_engine = SimpleIndexQueryEngine(index=index)
try:
result = query_engine.query("Summarize the content of the document.")
print("Query Result:", result)
except Exception as e:
print("Query execution error:", e)Real-World Applications of LlamaIndex
LlamaIndex isn’t just theoretical—it drives real innovations.
Semantic Search: Create search engines that understand user intent beyond keywords.
Chatbots over Documentation: Build chatbots that provide context-aware responses from structured documentation.
Data Augmentation for LLMs: Enhance LLM outputs by integrating diverse, well-organized data sources.
Key Takeaways and Next Steps
Streamlined Data Management: LlamaIndex organizes unstructured data into searchable, context-rich formats.
Versatile Applications: Its flexible components power everything from semantic search to intelligent chatbots.
Enhanced LLM Integration: By managing token limits and customizing prompts, LlamaIndex ensures optimal LLM performance.
Best Practices Matter: Modular design, robust testing, and security measures are key to building reliable applications.
Next Article Preview:
Fine-tuning hybrid search (combining vector and keyword methods)
Deploying LlamaIndex using containerized or serverless environments
Benchmarking performance and scaling strategies
Conclusion
LlamaIndex is more than just a tool — ’s a comprehensive framework for developing intelligent, context-aware applications. By streamlining data ingestion, structuring, querying, and output formatting, it empowers developers to leverage the full potential of LLMs. Whether you’re building a semantic search engine, a documentation chatbot, or augmenting your LLM with enriched context, this guide provides the foundation you need. For example, a fintech startup recently reduced data preparation time by 70% using LlamaIndex to process and query complex SEC filings. Join our community on Discord, explore our GitHub repository, and start building smarter applications today!
Author Bio:
I’m an experienced developer and data engineer specializing in LLM application development. My work with LlamaIndex has transformed how I manage data and build scalable applications. I regularly contribute to open-source projects and share insights on modern data practices. Connect with me on GitHub and join our Discord community for collaboration and support.
Call to Action:
Explore the LlamaIndex documentation, try out the code examples, and contribute to our GitHub repository. Share your projects in our community forum and help shape the future of LLM development!
For further discussion, collaboration, or to access our full GitHub repository with well-documented code, please contact us through the direct message.