

LLM Inference at Scale: The Ultimate Guide to Building Lightning-Fast AI APIs
This is How OpenAI Runs It.

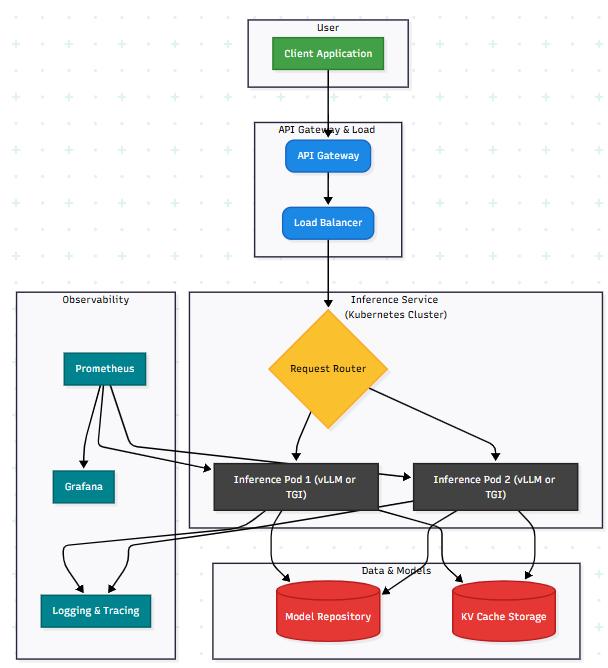
Detailed Briefing Document: Architecting High-Performance LLM Inference Systems
Executive Summary
Deploying Large Language Models (LLMs) in production is an online, real-time process where performance is paramount, focusing on achieving low latency, high throughput, and efficient memory usage. This document details the fundamental challenges, key optimiza…
