

MCP: The USB-C for AI Agents – Say Goodbye to Glue Code Forever!
Plug In. Power Up. Welcome to AI’s USB-C.

Building of MCP Server from Scratch
MCP Client calling Reference MCP Server
Test your MCP server with Claude Desktop
🔌 Still wiring AI models manually to APIs and data sources? That era is over.
Welcome to the Model Context Protocol (MCP) — the USB-C of AI integration that eliminates brittle glue code, simplifies tool orchestration, and unlocks true plug-and-play intelligence. In this video, you’ll explore how MCP empowers agentic workflows, Live RAG, dynamic tool discovery, and secure enterprise-ready AI pipelines.
🚀 If you’re building intelligent applications without MCP, you’re scaling the old way. Don’t get left behind.
⚙️ Say goodbye to the M x N glue code nightmare. MCP is here to unify AI integration.
In this deep-dive video, we unpack the Model Context Protocol (MCP) – the universal standard revolutionizing how AI models interact with tools, APIs, databases, and services. Learn how MCP transforms traditional RAG into Live RAG, supports agentic loops with human-in-the-loop approval, and enables secure, observable, modular AI systems in production.
You'll discover:
The core M-C-P framework and architecture (Model, Context, Protocol)
JSON-RPC message structure and transport (STDIO, HTTP + SSE)
How MCP powers live, real-time information flow into LLMs
Enterprise-grade observability, evaluation metrics, and root cause debugging
Security best practices: prompt shielding, OAuth 2.1, and API secret management
🔐 Whether you’re an AI architect, platform engineer, or GenAI dev, this is the foundational protocol you’ll soon be building on.
🧠 MCP is more than a spec — it's the backbone of intelligent, interconnected agents.
🔔 Subscribe for more deep dives on GenAI architectures, prompt ops, and enterprise AI tooling.
#ModelContextProtocol #MCP #AgenticAI #LiveRAG #LLMArchitecture #GlueCodeKiller #AIIntegration #EnterpriseAI #GenAIPlatform #MLOps #LLMOps #OpenAIAgents
The MCP Blueprint: A Developer's Guide to Building Enterprise-Grade AI Pipelines
Introduction: Beyond Glue Code — Architecting the Future of AI Integration
In the rapidly evolving landscape of artificial intelligence, the power of Large Language Models (LLMs) has been firmly established. Yet, their true potential has long been constrained by a fundamental challenge: isolation. Even the most advanced models are, by default, disconnected from the live, dynamic data and specialized tools that drive modern enterprises. This has led to a significant architectural bottleneck known as the "M × N problem," where connecting M different AI models to N different data sources, APIs, and services requires a combinatorial explosion of custom, brittle integration code. This "glue code" is not only time-consuming and expensive to develop but also creates fragile systems that are difficult to scale and maintain. Each new tool or API integration has historically been a bespoke project, akin to the pre-USB era where every peripheral device required its own proprietary cable and driver.
This is the challenge that the Model Context Protocol (MCP) was engineered to solve. Introduced by Anthropic in November 2024, MCP is an open standard designed to be the universal connector for AI—the "USB-C for AI". It provides a standardized, model-agnostic interface that allows AI systems to interact with external data sources and tools in a secure, repeatable, and scalable manner. Its significance was immediately recognized, with rapid adoption by industry leaders including OpenAI, Google DeepMind, and Microsoft, cementing its status as a foundational primitive for the emerging AI-native era. MCP replaces the tangled mess of custom connectors with a single, extensible protocol, enabling a plug-and-play ecosystem where any compliant AI can interact with any compliant tool.
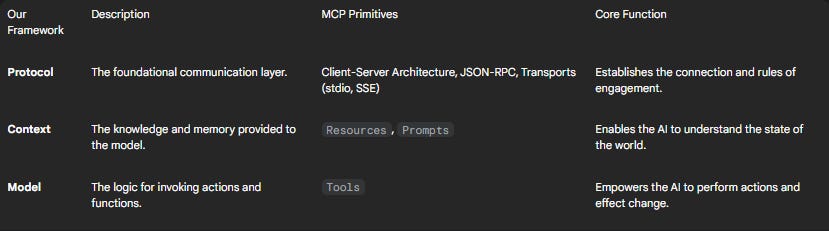
To navigate this new paradigm, this report introduces a clear mental model for designing MCP-based systems: the M-C-P Framework. This framework deconstructs AI pipelines into three distinct but interconnected layers, which map directly to the core primitives of the protocol itself:
Model: The invocation logic that empowers an AI to become an agent capable of performing actions.
Context: The mechanisms for providing the AI with situational understanding, memory, and knowledge.
Protocol: The foundational input/output standards and communication architecture that make interaction possible.
The table below provides a legend for how this conceptual framework aligns with the technical components of MCP, a structure that will guide this entire report.
MCP's impact, however, extends far beyond simplifying connections. It serves as a powerful architectural catalyst, fundamentally reshaping how intelligent systems are designed. By standardizing the interface between models and tools, MCP decouples the AI's reasoning capabilities from the execution of specific functions. This decoupling has profound implications. It means a developer can build a specialized tool—for instance, an MCP server for interacting with a Stripe payment API—just once, and it can then be discovered and used by any compliant AI model, whether it's from Anthropic, OpenAI, or Google.
This fosters a rich, composable ecosystem of reusable components, making it inefficient to build a single, monolithic AI agent that attempts to do everything. Instead, the industry is shifting toward an "Agentic AI Mesh," where complex, multi-step business processes are solved by orchestrating fleets of smaller, specialized agents that collaborate via MCP. In this new reality, MCP is more than just a connector; it is the foundational nervous system for this distributed intelligence. Much as REST APIs enabled the microservices revolution and Apache Kafka became the backbone of the modern data stack, MCP provides the universal language for the modern AI stack, turning AI from an isolated black box into a first-class citizen of the enterprise platform. Architects and developers must therefore design not just for connecting a model to a tool, but for participating in this new, decentralized world of collaborative AI.
Section 1: The Protocol — Forging the Connection
This section dissects the foundational layer of the Model Context Protocol, explaining how connections are established, messages are exchanged, and data is transported. This is the "P" in our M-C-P framework—the underlying rules of engagement that make all higher-level interactions possible.
The MCP Architecture: A Triad of Host, Client, and Server
The MCP architecture is designed for modularity and security, revolving around a client-host-server pattern that clearly separates concerns and enables robust communication. This triad consists of three distinct components that work in concert to bridge the gap between an LLM and the outside world.
Host: The Host is the application where the LLM "lives" and where the end-user interacts. This could be an AI-powered IDE like Cursor, a desktop assistant like Claude Desktop, or a custom-built web application or chatbot. The Host acts as the primary orchestrator and security gatekeeper. It is responsible for managing the lifecycle of client connections, enforcing security policies, handling user authorization and consent for actions, and aggregating context from multiple different MCP servers to present a unified view to the LLM.
Client: The MCP Client is a lightweight protocol client, typically embedded within the Host application. Its primary role is to act as a "universal translator," managing a dedicated, one-to-one connection with a single MCP Server. The Client is responsible for speaking the language of the protocol—sending and receiving structured JSON-RPC messages—and abstracting the complexities of the connection away from the Host application.
Server: The MCP Server is a lightweight, independent program that acts as a wrapper or adapter for an external system, such as a database, a third-party API, or a local file system. The server's job is to expose the capabilities of that external system in a standardized format that any MCP Client can understand. It does this by defining a set of
Tools,Resources, andPromptsthat correspond to the functions and data of the system it represents.
This architectural separation is critical. It allows server developers to focus solely on exposing their specific service's capabilities without worrying about the intricacies of different LLMs or host applications. Conversely, host developers can integrate a vast array of tools simply by connecting to their respective MCP servers, without needing to write custom integration code for each one.
The Communication Handshake: Speaking JSON-RPC
At its heart, MCP is a stateful session protocol built upon the well-established and widely understood JSON-RPC 2.0 standard. This choice ensures a robust, structured, and language-agnostic communication framework. All interactions between a client and a server are conducted through three primary message types :
Requests: Bidirectional messages that specify a
methodto be invoked andparamsfor that method. A request always expects a response.Responses: Messages sent in reply to a request, containing either a
result(on success) or anerrorobject. They are correlated with requests via anid.Notifications: One-way messages that do not require a response. They are used for events or acknowledgments where a reply is unnecessary.
The connection between a client and server follows a well-defined lifecycle to ensure that both parties are synchronized and aware of each other's capabilities before any substantive communication occurs :
Initialization: The lifecycle begins when the client sends an
initializerequest to the server, declaring its supported protocol version and capabilities. The server replies with its own version and capabilities. This handshake ensures compatibility. Once the server responds, the client sends aninitializednotification to confirm that the connection is fully established and ready for operation.Operation: During this phase, the client and server engage in the normal exchange of requests, responses, and notifications to list and invoke tools, retrieve resources, and pass data.
Termination: The connection can be gracefully closed by either party. This ensures a clean shutdown of the session and any associated processes.
Robust error handling is built into the protocol, with standardized JSON-RPC error codes for common issues such as 32700 (Parse Error), 32601 (Method not found), and 32602 (Invalid params). This standardization is crucial for building resilient, production-grade applications that can gracefully handle and recover from communication failures.
Choosing Your Transport Layer: Local vs. Remote
MCP is transport-agnostic, but two primary transport mechanisms have been standardized to cover the most common deployment scenarios: local and remote communication. The choice of transport is a fundamental architectural decision that impacts security, scalability, and implementation complexity.
STDIO (Standard Input/Output): This transport is designed for local inter-process communication, where the MCP server is running on the same machine as the host application. Communication happens over the standard input (
stdin) and standard output (stdout) streams. This is the ideal choice for tools that need to interact with the local environment, such as accessing the file system, running shell commands, or interacting with a local Git repository. Its primary advantages are simplicity and security; because it doesn't open any network ports, the attack surface is significantly reduced.HTTP + SSE (Server-Sent Events): This transport is the standard for remote, networked services where the MCP server is accessible over the internet or a private network. It uses standard HTTP for client-to-server requests and Server-Sent Events (SSE) for server-to-client notifications, enabling a persistent, real-time, and bidirectional communication channel. This is the transport you would use to connect an AI assistant to a cloud-based API, a remote database, or any other web service. While more powerful and scalable, it introduces the need for network security measures like TLS encryption and robust authentication mechanisms. Advanced frameworks like
mcp-frameworkalso offer anHTTP Streamtransport, which further optimizes this pattern.
The following table provides a clear, at-a-glance comparison to guide the selection of the appropriate transport protocol.

Section 2: The Context — Empowering Models with Knowledge
This section explores the "C" of our framework, focusing on how to provide LLMs with the essential information—the context—they need to generate relevant, accurate, and grounded responses. In MCP, context is not just a blob of text; it is delivered through two specific, structured primitives: Resources and Prompts. These primitives give the model its "senses," allowing it to perceive and understand the state of the world it needs to operate in.
Exposing Data with Resources
In the MCP ecosystem, a Resource is the primary primitive for exposing read-only data and content to an LLM. Functionally,
Resources are analogous to GET requests in a RESTful API; they are designed to retrieve information without causing side effects or performing significant computation. They are the mechanism by which an AI agent can "read" from the world, whether that means accessing a file, querying a database record, or fetching a configuration setting.
The official MCP SDKs provide simple and elegant ways to define these resources. For example, using the Python SDK, developers can use the @mcp.resource() decorator to expose a function as a resource. This can be done for both static and dynamic data.
Static Resources: These are used for exposing data that is fixed or changes infrequently. A common use case is providing a system-wide configuration file or a policy document that the AI may need to consult. The resource handler simply returns the static content.
Python SDK Example: Static Configuration Resource
Python
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("MyAppServer")
@mcp.resource("config://app", title="Application Configuration")
def get_config() -> str:
"""Returns the static application configuration data."""
# In a real app, this might read from a YAML or JSON file.
return "log_level: INFO\nfeature_flags:\n - new_dashboard\n"
Dynamic Resources: This is where the power of
Resourcestruly shines. They allow for the on-demand retrieval of specific pieces of data, often identified by a unique URI. The protocol supports URI templates with placeholders, allowing a client to request a specific entity. This pattern is essential for providing real-time, targeted context to the AI.Python SDK Example: Dynamic User Profile Resource
Python
from mcp.server.fastmcp import FastMCP
from typing import Dict, Any
mcp = FastMCP("UserManagementServer")
# This resource can be called with URIs like "users://123/profile"
@mcp.resource("users://{user_id}/profile", title="User Profile")
def get_user_profile(user_id: str) -> Dict[str, Any]:
"""Retrieves a user's profile from the database."""
# In a real app, this would query a database.
db = {"123": {"name": "Alice", "role": "admin"}, "456": {"name": "Bob", "role": "user"}}
return db.get(user_id, {"error": "User not found"})
This ability to fetch fresh, specific data at runtime is a cornerstone of building context-aware AI systems and forms the basis for advanced patterns like "Live RAG," which will be explored later in this report.
Structuring Interactions with Prompts
While Resources provide the raw data, Prompts provide structure and guidance for how the LLM should interact with that data or perform complex, multi-step tasks. A
Prompt in MCP is a reusable, server-defined template that can be invoked by the client. They are designed to enforce consistency, ensure quality, and encapsulate best practices for common workflows.
Instead of having the user or the host application craft a complex prompt from scratch every time, they can simply invoke a pre-defined prompt from the server, filling in the necessary parameters. This is particularly useful for tasks that require a specific format, tone, or chain of reasoning.
The Python SDK's @mcp.prompt() decorator makes creating these templates straightforward.
Python SDK Example: Standardized Code Review Prompt
Python
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("DevToolsServer")
@mcp.prompt(title="Standard Code Review")
def review_code(code: str) -> str:
"""Generates a standardized prompt for reviewing a piece of code."""
return f"""
Please review the following code snippet for quality, correctness, and adherence to best practices.
Provide your feedback in a structured format with sections for "Strengths", "Areas for Improvement", and "Specific Suggestions".
Code to review:
```python
{code}
```
"""
Python SDK Example: Multi-Turn Debugging Assistant Prompt
Python
from mcp.server.fastmcp import FastMCP
from mcp.server.fastmcp.prompts import base
mcp = FastMCP("DevToolsServer")
@mcp.prompt(title="Debugging Assistant")
def debug_error(error: str) -> list[base.Message]:
"""Initiates a multi-turn conversation to debug an error."""
return
In this second example, the prompt returns a list of messages, effectively setting up the initial state of a conversation for the LLM. By defining these interaction patterns on the server, organizations can maintain control over the quality and consistency of their AI-driven workflows, ensuring that models behave in a predictable and desirable manner.
Section 3: The Model — Giving AI the Power to Act
This section addresses the "M" in our framework, focusing on the mechanisms that transform a passive LLM into an active, intelligent agent. If Resources and Prompts give the model its senses and memory, it is the Tool primitive that gives it hands—the ability to execute functions, interact with systems, and effect change in its environment. This is the heart of agentic AI.
Defining Capabilities with Tools
In the MCP specification, a Tool is an executable function that an LLM can discover and invoke through the client.
Tools represent active operations, making them analogous to POST, PUT, or DELETE requests in a REST API. They are the mechanism through which an AI can perform actions like creating a file, sending a message, querying a database for analysis, or triggering a CI/CD pipeline.
The power of this system lies in its discoverability. The AI model doesn't need to have prior, hardcoded knowledge of the tools. Instead, it learns about them at runtime by inspecting their schemas.
Schema is Everything: The Contract with the AI
The critical component of any Tool is its input schema. This schema serves as a machine-readable "contract" that tells the LLM three crucial things:
What the tool is: The
nameanddescriptionof the tool.What it needs: The parameters the tool accepts, their types, and whether they are required.
What it does: The description provides natural language context that the LLM uses to decide when to use the tool.
A well-defined schema is paramount. Without it, the LLM cannot reliably understand or use the tool. Modern MCP frameworks and SDKs make schema definition a first-class citizen.
In Python: The official
mcp-python-sdkleverages Python's type hints, often in conjunction with Pydantic models, to automatically generate the required JSON schema. This ensures that the code and the schema are always in sync.Python SDK Example: Tool with Type Hints
Python
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("CalculatorServer")
@mcp.tool()
def calculate_bmi(weight_kg: float, height_m: float) -> float:
"""Calculate Body Mass Index (BMI) given weight in kg and height in meters."""
if height_m <= 0:
raise ValueError("Height must be positive.")
bmi = weight_kg / (height_m ** 2)
return round(bmi, 2)
In TypeScript: Frameworks like
mcp-frameworktake this a step further by making Zod schemas a mandatory part of tool definition. Zod provides not only type safety but also powerful validation capabilities. A critical best practice in this ecosystem is to provide a detailed.describe()annotation for every single field in the schema. This description is not just for human developers; it is the primary documentation that the LLM reads to understand how to correctly populate the tool's arguments.TypeScript/Zod Example: Data Fetcher Tool
TypeScript
import { MCPTool, McpInput } from "mcp-framework";
import { z } from "zod";
// The schema defines the tool's inputs with types, validation, and descriptions.
const DataFetcherSchema = z.object({
url: z.string().url().describe("The URL of the API endpoint to fetch data from."),
method: z.enum().default("GET").describe("The HTTP method to use for the request."),
timeout: z.number().positive().default(5000).describe("Request timeout in milliseconds.").optional()
});
class DataFetcher extends MCPTool {
name = "fetch_api_data";
description = "Fetches data from an external API endpoint.";
schema = DataFetcherSchema;
async execute(input: McpInput<this>) {
// The 'input' object is fully typed based on the Zod schema.
const { url, method, timeout } = input;
//... implementation to fetch data using the provided parameters...
return `Successfully fetched data from ${url}`;
}
}
The Agentic Loop in Action: A Step-by-Step Walkthrough
The process by which an AI agent uses a tool is a sophisticated, multi-step dance orchestrated by the Host application. This "agentic loop" ensures that the AI's actions are intentional, approved, and correctly executed.
Discovery: The loop begins when the Host application's Client connects to an MCP Server. The Client sends a
tools/listrequest to the server, which responds with a list of all available tools and their detailed JSON schemas.Reasoning: A user provides a prompt to the Host application, for example, "What is the current stock price of Apple Inc.?". The Host takes this user prompt and augments it with the list of available tools (specifically, their names, descriptions, and schemas) before sending the entire package to the LLM. The LLM analyzes this combined input. Using its advanced reasoning and function-calling capabilities, it determines that the user's query can be best answered by the
get_stock_pricetool and that thetickerparameter should be"AAPL".Approval (Human-in-the-Loop): This is a crucial step for security and control. The LLM does not execute the tool directly. Instead, it returns its intent to the Host application, specifying the tool it wants to call and the arguments it has formulated (e.g.,
call get_stock_price(ticker='AAPL')). The Host application must then present this intended action to the human user for explicit approval. The user acts as the final gatekeeper, preventing the AI from taking unintended or malicious actions.Invocation: Once the user approves the action, the Host instructs its Client to proceed. The Client constructs a formal
tools/callJSON-RPC request containing the tool name and parameters and sends it to the MCP Server.Execution: The MCP Server receives the
tools/callrequest, validates the parameters against the tool's schema, and executes the corresponding function in its codebase (e.g., calling a financial data API).Synthesis: The MCP Server sends the result of the execution (e.g.,
{"price": 173.22}) back to the Client in a JSON-RPC response. The Host receives this result and passes it back to the LLM, often with a prompt like, "Theget_stock_pricetool returned the following result. Please use it to formulate a final answer for the user." The LLM then synthesizes the structured data into a natural, human-readable response, such as, "The current stock price for Apple Inc. (AAPL) is $173.22."
This complete loop, from user query to reasoned action and synthesized response, is the fundamental pattern that enables the creation of powerful and reliable agentic AI systems.
Section 4: End-to-End Project: Building a "Live RAG" Financial Analysis Agent
This section transitions from theory to practice, providing a comprehensive, hands-on tutorial that integrates all the concepts from the M-C-P framework. We will build a complete, production-style application: a financial analysis agent that performs Retrieval-Augmented Generation (RAG) directly from a live database. This "Live RAG" approach showcases a modern and powerful use of MCP, as it bypasses the need for pre-processing data into a separate vector store, instead querying fresh, structured information on demand.
Part 1: Project Scaffolding and Database Setup
The first step is to establish the foundation for our project, including the development environment and the live data source that our agent will query.
Objective: Create a Python project and a local SQLite database to serve as our real-time source of financial information.
Steps:
Initialize the Project Environment: A best practice for modern Python development is to use a dedicated environment and package manager. We will use
uv, a fast and reliable choice recommended by the official MCP Python SDK documentation.Bash
# Create a new project directory
mkdir mcp-financial-agent && cd mcp-financial-agent
# Initialize a virtual environment with uv
uv venv
source.venv/bin/activate
Install Dependencies: We need the MCP Python SDK (
mcp) with its command-line interface (cli) for running the server, andaiosqliteto interact with our SQLite database asynchronously, which is a requirement forfastmcpresource and tool handlers.Bash
uv pip install "mcp[cli]" aiosqlite
Create the Live Database: We will write a Python script (
setup_db.py) to create and populate a local SQLite database namedfinancials.db. This database will contain two tables, simulating a live data feed.stock_prices: Will store daily open, high, low, close, and volume (OHLCV) data for various tickers.financial_news: Will store timestamped news headlines and article summaries associated with specific tickers.
setup_db.pyPython
import sqlite3
import os
# Ensure db directory exists
os.makedirs('db', exist_ok=True)
DB_PATH = 'db/financials.db'
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
# Create stock_prices table
cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_prices (
id INTEGER PRIMARY KEY,
ticker TEXT NOT NULL,
date TEXT NOT NULL,
open REAL NOT NULL,
high REAL NOT NULL,
low REAL NOT NULL,
close REAL NOT NULL,
volume INTEGER NOT NULL,
UNIQUE(ticker, date)
)
''')
# Create financial_news table
cursor.execute('''
CREATE TABLE IF NOT EXISTS financial_news (
id INTEGER PRIMARY KEY,
ticker TEXT NOT NULL,
timestamp TEXT NOT NULL,
headline TEXT NOT NULL,
summary TEXT NOT NULL
)
''')
# Insert sample data (in a real app, this would be a continuous feed)
sample_prices =
sample_news =
cursor.executemany('INSERT OR IGNORE INTO stock_prices (ticker, date, open, high, low, close, volume) VALUES (?,?,?,?,?,?,?)', sample_prices)
cursor.executemany('INSERT OR IGNORE INTO financial_news (ticker, timestamp, headline, summary) VALUES (?,?,?,?,?)', sample_news)
conn.commit()
conn.close()
print("Database 'financials.db' created and populated successfully.")
Running
python setup_db.pywill create our data source.
Part 2: Implementing the Context Layer (Live Retrieval)
Now, we will build the MCP server and expose our database tables as Resources. This is the "Context" layer of our agent, enabling it to retrieve fresh information directly from the source.
Objective: Create an MCP server that provides access to news articles via a dynamic Resource.
Implementation (server.py):
We will create our main server file, server.py, and use the @mcp.resource() decorator to define our retrieval mechanism. This demonstrates the "Live RAG" pattern: the agent can fetch context on demand without an intermediate vectorization step.
server.py (Partial)
Python
import aiosqlite
from mcp.server.fastmcp import FastMCP
from typing import List, Dict, Any
# Initialize the MCP Server
mcp = FastMCP("FinancialAnalysisServer")
DB_PATH = "db/financials.db"
@mcp.resource("news://{ticker}")
async def get_news_for_ticker(ticker: str) -> List]:
"""
Retrieves the latest news articles for a given stock ticker.
This serves as the 'retrieval' step in our Live RAG pipeline.
"""
async with aiosqlite.connect(DB_PATH) as conn:
conn.row_factory = aiosqlite.Row
cursor = await conn.execute(
"SELECT headline, summary, timestamp FROM financial_news WHERE ticker =? ORDER BY timestamp DESC LIMIT 5",
(ticker.upper(),)
)
rows = await cursor.fetchall()
await cursor.close()
# Convert rows to a list of dictionaries for JSON serialization
return [dict(row) for row in rows]
This code defines a dynamic resource that can be accessed with a URI like news://TSLA. When invoked, it queries the SQLite database for the latest five news items for the specified ticker and returns them as structured data. This is the core of our on-demand retrieval system.
Part 3: Implementing the Model's Toolbox
Next, we give our agent the ability to perform calculations and analysis by defining Tools. This is the "Model" layer, where we grant the AI the power to act.
Objective: Add analytical functions to our MCP server as invokable Tools.
Implementation (server.py):
We will extend server.py by adding functions decorated with @mcp.tool(). These tools will perform calculations on the data in our stock_prices table. We use Python type hints to ensure the MCP SDK can automatically generate the correct input schemas for the LLM.
server.py (Continued)
Python
#... (imports and resource from Part 2)...
@mcp.tool()
async def calculate_moving_average(ticker: str, window_size: int = 20) -> float:
"""
Calculates the simple moving average (SMA) for a given stock ticker
over a specified number of days (window_size).
"""
async with aiosqlite.connect(DB_PATH) as conn:
cursor = await conn.execute(
"SELECT close FROM stock_prices WHERE ticker =? ORDER BY date DESC LIMIT?",
(ticker.upper(), window_size)
)
rows = await cursor.fetchall()
await cursor.close()
if len(rows) < window_size:
raise ValueError(f"Not enough data to calculate {window_size}-day SMA.")
prices = [row for row in rows]
sma = sum(prices) / len(prices)
return round(sma, 2)
@mcp.tool()
async def get_price_range(ticker: str, days: int = 30) -> Dict[str, float]:
"""
Finds the highest and lowest stock price for a ticker over a specified number of days.
"""
async with aiosqlite.connect(DB_PATH) as conn:
cursor = await conn.execute(
"SELECT MIN(low), MAX(high) FROM (SELECT low, high FROM stock_prices WHERE ticker =? ORDER BY date DESC LIMIT?)",
(ticker.upper(), days)
)
row = await cursor.fetchone()
await cursor.close()
if not row or row is None:
return {"error": "No price data found for the period."}
return {"low": round(row, 2), "high": round(row, 2)}
# Entry point to run the server
if __name__ == "__main__":
print("Starting Financial Analysis MCP Server...")
mcp.run(transport="stdio")
Our server is now complete. It can retrieve news (Resource) and perform calculations (Tools).
Part 4: Developing the Agentic Client & Orchestration
The final piece is the client application—the "brain" that uses an LLM to orchestrate the tools and resources we've built. For this, it is a best practice to use a higher-level agentic framework, which simplifies the complex logic of managing the conversation, reasoning, and tool-calling loop.
Objective: Create a client that takes a natural language query, uses an LLM to create a plan, executes the plan using our MCP server, and synthesizes a final answer.
Implementation (client.py):
We will use the langchain-mcp-adapters library, which provides a seamless way to load MCP tools into a LangChain or LangGraph agent. This approach abstracts away the low-level details of the agentic loop.
client.py
Python
import asyncio
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
import os
# Ensure OpenAI API key is set
# os.environ["OPENAI_API_KEY"] = "your-api-key"
# Define the LLM for the agent
model = ChatOpenAI(model="gpt-4o")
# Define how to connect to our MCP server
server_params = StdioServerParameters(
command="python",
args=["server.py"], # This runs our server script
)
async def run_financial_agent(query: str):
print(f"\nUser Query: {query}")
print("Agent is thinking...")
# Connect to the MCP server
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
# Load all tools and resources from the server
mcp_tools = await load_mcp_tools(session)
# Create a ReAct agent using LangGraph
agent_executor = create_react_agent(model, mcp_tools)
# Invoke the agent with the user's query
final_response = ""
async for event in agent_executor.astream_events({"messages": [("user", query)]}, version="v1"):
kind = event["event"]
if kind == "on_chat_model_stream":
content = event["data"]["chunk"].content
if content:
print(content, end="", flush=True)
elif kind == "on_tool_end":
print(f"\nTool Used: {event['name']}, Output: {event['data']['output']}")
final_response = event['data']['output']
# The final synthesis happens in the last LLM call
# For simplicity, we can also just grab the last AIMessage from the state
final_state = await agent_executor.ainvoke({"messages": [("user", query)]})
final_answer = final_state['messages'][-1].content
print(f"\n\nFinal Synthesized Answer:\n{final_answer}")
async def main():
user_query = "Give me a summary of TSLA's performance over the last 30 days, including its 20-day moving average and any recent news."
await run_financial_agent(user_query)
if __name__ == "__main__":
asyncio.run(main())
To run the entire application, you would simply execute python client.py in your terminal. The client script will automatically start the server.py process and connect to it. The LangGraph agent will then receive the user query, inspect the tools and resources provided by the server, and formulate a plan. It will autonomously call get_price_range, calculate_moving_average, and access the news://TSLA resource, feeding the results back into its reasoning loop to generate a final, comprehensive summary. This end-to-end project demonstrates a powerful, modern, and repeatable pattern for building structured AI pipelines with MCP.
Section 5: From Prototype to Production: Enterprise-Scale Operations
Building a functional prototype is only the first step. To deploy our financial agent—or any MCP-based application—in a real-world enterprise environment, we must address a host of critical non-functional requirements. This section covers the essential practices for hardening, monitoring, and scaling MCP pipelines, transforming them from experiments into robust, production-grade services. The introduction of MCP creates a new, distinct layer in the AI stack, and this layer requires its own dedicated operational practices.
Fortifying Your Pipeline: A Security Deep Dive
Security is paramount when connecting powerful AI models to sensitive enterprise data and systems. The MCP architecture, while standardized, is not inherently secure; its security depends entirely on how it is implemented and deployed. A comprehensive security strategy must address authentication, authorization, and threat mitigation across the entire pipeline.
Authentication & Authorization: Beyond Simple API Keys
For local, stdio-based servers, security is simpler as there are no open network ports. However, for remote servers accessible over HTTP, robust authentication is non-negotiable. While simple API keys can be used for initial development, they are insufficient for production as they represent static, long-lived credentials that can be leaked or stolen.
The industry best practice and the recommended standard for securing remote MCP servers is OAuth 2.1 with PKCE (Proof Key for Code Exchange). This protocol ensures that only properly authenticated and authorized clients can access the server. The MCP specification has evolved to support delegating user authentication to external, enterprise-grade identity providers like Microsoft Entra ID or Google Identity, meaning developers don't have to build their own authentication servers from scratch. This allows the MCP server to enforce that the AI agent can only perform actions that the authenticated human user is permitted to perform.
Threat Mitigation
Deploying MCP servers introduces new potential attack vectors that require specific mitigation strategies. The following threat model outlines the most significant risks and the corresponding best practices for addressing them.

Achieving Full-Stack Observability
Without proper instrumentation, agentic AI systems can become "black boxes," making it nearly impossible to debug issues, optimize performance, or understand costs. When our financial agent provides a slow or incorrect answer, we need to know why. Was it a slow database query in a
Resource? Did the LLM choose an inefficient sequence of Tools? Was there high latency in the LLM's own response time? Answering these questions requires deep, end-to-end observability.
Tracing the Agent's Mind
The first step is to gain tracing visibility into the entire lifecycle of an MCP request. Modern Application Performance Monitoring (APM) solutions like New Relic are now offering native MCP support, which can automatically instrument the interactions between the client and server. This allows developers to visualize the agent's decision-making process in a clear waterfall diagram, showing:
The exact sequence of tool and resource invocations for a given user prompt.
The inputs provided to each tool and the outputs it returned.
The latency of each step, including the MCP server's execution time and the network round-trip time.
This detailed tracing is invaluable for pinpointing bottlenecks and debugging the agent's logical flow.
Monitoring for Performance & Cost
Beyond tracing individual requests, it's crucial to monitor aggregate metrics to understand the overall health, performance, and cost of the AI pipeline. For our financial agent, key performance indicators (KPIs) to track in a monitoring dashboard (e.g., using Grafana) would include :
Tool Latency: The average and p95 latency for each tool (
calculate_moving_average,get_price_range). A spike could indicate a database performance issue.Tool Error Rate: The percentage of tool calls that result in an error. This helps identify buggy or unreliable tools.
Tool Usage Patterns: A frequency count of which tools are used most often. This can inform optimization efforts and reveal how users are interacting with the agent.
Token Consumption: The number of input and output tokens consumed by the LLM for both the reasoning (tool selection) and synthesis (final answer generation) steps. This is a direct driver of operational cost and is essential for financial management.
Deployment and Scalability
To deploy our MCP server to production, we must follow standard DevOps best practices to ensure it is scalable, resilient, and maintainable.
Containerization: The first step is to package our Python-based MCP server into a Docker container. The
Dockerfilewill define a reproducible environment by specifying the base Python image, copying the application code, installing dependencies viauv pip, and exposing the necessary port for HTTP-based transport. This ensures the server runs consistently across all environments, from a developer's laptop to the production cloud.Orchestration: While a single container can be run on a virtual machine, a truly scalable and fault-tolerant deployment requires a container orchestration platform like Kubernetes or a managed serverless offering such as Google Cloud Run or AWS ECS. These platforms handle critical tasks like load balancing traffic across multiple server instances, automatically scaling the number of instances based on demand (e.g., using a Horizontal Pod Autoscaler), and restarting unhealthy instances that fail their health checks.
CI/CD (Continuous Integration/Continuous Deployment): The entire deployment process should be automated through a CI/CD pipeline, using tools like GitHub Actions or GitLab CI. A typical pipeline for our MCP server would be triggered on a push to the main branch and would automatically:
Run unit and integration tests.
Build the Docker image.
Push the image to a container registry (e.g., Docker Hub, Google Artifact Registry).
Deploy the new image to the production orchestration platform using a safe deployment strategy like blue-green or canary to minimize downtime and risk.
Section 6: Measuring Success: Evaluating Your AI Pipeline's Performance
Once an AI pipeline is deployed, the work is not over. It is crucial to have a rigorous, quantitative framework for evaluating its performance. For our "Live RAG" financial agent, simply observing that the answers "look good" is insufficient. We need objective metrics to measure the quality of its responses, identify areas for improvement, and track progress over time. The unique nature of our "Live RAG" system, which retrieves structured data directly rather than from a vector store, requires a tailored evaluation approach.
Setting Up the Evaluation Harness
The foundation of any robust evaluation process is a high-quality test dataset and an automated framework to run the tests.
The "Golden" Dataset: The first and most critical step is to create a "golden" dataset. This consists of a representative set of input questions and their corresponding ground-truth, or "golden," answers. For our financial agent, this dataset would include a diverse range of questions designed to test all its capabilities:
Simple Retrieval: "What was the closing price of TSLA on June 2nd, 2025?" (Golden answer: 189.7)
Tool Use: "What was the 20-day simple moving average for TSLA on June 2nd, 2025?" (Golden answer: A pre-calculated, correct numerical value)
RAG/Synthesis: "Summarize the recent news for TSLA." (Golden answer: A human-written summary containing the key facts from the sample news articles in our database)
Automated Evaluation Framework: Manually evaluating each response is not scalable. We will use an open-source framework like Ragas to automate the evaluation process. Ragas is well-suited for this task as it can use LLMs as judges to score the quality of the generated outputs against the golden dataset.
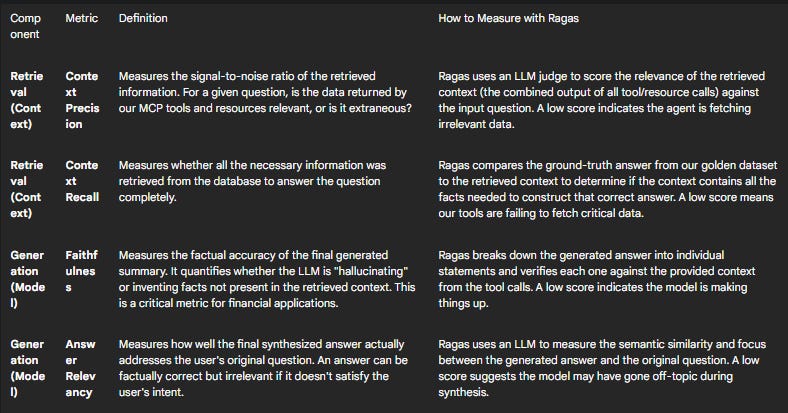
Component-Level Evaluation: Isolating Retrieval and Generation
A RAG system's final output quality is a function of two distinct components: the retrieval of context and the generation of the final answer. A failure in either component will lead to a poor result. Therefore, it is essential to evaluate them separately to perform effective root cause analysis.
For our "Live RAG" agent, "retrieval" refers to the context gathered by invoking our MCP Resources and Tools. "Generation" refers to the final natural language summary synthesized by the LLM from that retrieved context. The following table outlines a tailored set of metrics for evaluating our agent.
Root Cause Analysis and Iterative Improvement
This evaluation framework is not a one-time check; it is a tool for continuous, iterative improvement. By analyzing the scores for these metrics, developers can diagnose specific problems within the pipeline.
If Context Recall is consistently low, it points to a problem in our MCP server's
ToolsorResources. Perhaps the SQL query in theget_news_for_tickerresource is too restrictive, or thecalculate_moving_averagetool is not fetching a large enough data window. The solution is to refine the logic within the MCP server.If Faithfulness is low, but context metrics are high, the problem lies with the LLM's generation step. The LLM is failing to ground its response in the provided data. The solution might involve improving the prompt template used for the final synthesis step, providing more explicit instructions to "only use the provided context," or switching to a more capable (and likely more expensive) LLM that is better at following instructions.
If Answer Relevancy is low, it could also be a prompt engineering issue, where the synthesis prompt is not correctly focusing the LLM on the user's original intent.
By systematically running the evaluation suite after each change, teams can objectively measure the impact of their modifications and confidently improve the quality, reliability, and trustworthiness of their AI systems.
Conclusion: The New Stack for Intelligent Applications
The Model Context Protocol represents a pivotal moment in the evolution of artificial intelligence, shifting the paradigm from isolated, monolithic models to a vibrant, interconnected ecosystem of specialized agents and services. By providing a universal, open standard for communication, MCP solves the intractable "M × N" integration problem, liberating developers from the endless cycle of writing brittle glue code and enabling them to build scalable, maintainable, and powerful AI systems.
This report has laid out the M-C-P Blueprint—a structured framework for architecting these modern AI pipelines:
We began with the Protocol, the foundational layer of Hosts, Clients, and Servers communicating via JSON-RPC. Understanding this architecture and its transport mechanisms is the first step to building any compliant system.
We then explored the Context layer, where
Resourcesprovide the AI with real-time, on-demand knowledge andPromptsprovide the structured guidance needed for consistent and high-quality interactions.Finally, we examined the Model layer, where
Toolsgive the AI the power to act, transforming it from a passive text generator into an active agent capable of executing functions and affecting change in the real world.
Through our end-to-end project, we demonstrated how these concepts converge to create a "Live RAG" agent—a powerful pattern that queries live, structured data directly, offering a more dynamic and timely alternative to traditional vector search-based RAG. Furthermore, we have addressed the critical enterprise requirements of security, observability, and evaluation, providing actionable strategies for deploying these systems in production with confidence.
The road ahead for the MCP ecosystem is clear and promising. We are on the cusp of seeing vibrant marketplaces for off-the-shelf MCP servers, where developers can browse and integrate pre-built capabilities for everything from payment processing to enterprise resource planning. The true power will be unlocked when AI agents can dynamically discover and chain tools from multiple, disparate MCP servers to solve complex, multi-domain problems without human intervention. This vision of a collaborative, composable, and autonomous "Agentic AI Mesh" is no longer science fiction; it is the logical endpoint of the architectural shift that MCP has set in motion.
For developers and architects, the message is clear. The future of intelligent applications is not about building bigger, all-knowing models. It is about connectivity, interoperability, and orchestration. The Model Context Protocol is not just another API standard; it is the architectural foundation for this new generation of connected AI. Mastering its principles is essential for anyone looking to build the intelligent, enterprise-grade applications of tomorrow.