

🎬Production-Ready Movie Recommendation System
movie recommendation system, similar to Netflix


This podcast offers a comprehensive guide to constructing a production-ready movie recommendation system, similar to Netflix, utilizing Amazon Web Services.
It details the architecture, incorporating vector search with FAISS (and a plan for future Pinecone integration), advanced embedding techniques using a two-tower model, and deployment via Docker and Kubernetes.
The resource (podcast and article) covers essential aspects such as data ingestion, user interaction tracking, embedding generation, API development, and infrastructure setup, emphasizing scalability, performance, security, and operational best practices.
Furthermore, it outlines strategies for transitioning to a managed vector database and ensuring the system's reliability and cost-effectiveness.
Ultimately, this resource (podcast and article) offers a practical blueprint for building and deploying a sophisticated recommendation engine.
Personalized recommendations are the cornerstone of modern streaming platforms. In this guide, we will build an end-to-end movie recommendation system that leverages vector search for personalization.
We start with FAISS for fast similarity search (with a future migration path to Pinecone), implement advanced embedding techniques using a two-tower model, and deploy the system on AWS using Docker and Kubernetes.
This guide emphasizes production-grade details, including persistence, caching, real-time data ingestion, robust security, and operational excellence.
1. Introduction
Modern content platforms rely on personalized recommendations to drive user engagement and content discovery. By representing movies and user interactions as dense vector embeddings, we can power recommendations using a similarity search. Our solution combines
Content-based Filtering: Leverages movie metadata (plot summaries, genres, etc.).
Collaborative Filtering: Incorporates user interactions (views, ratings).
Advanced Embedding Generation: Uses a two-tower neural network with attention/time-decay mechanisms for robust user embeddings.
Robust Infrastructure: A centralized FAISS service with persistence (via S3 and Redis caching), real-time updates via Kafka/Kinesis, OAuth2-based security with RBAC, and deployment on AWS (EKS, RDS, S3) with Docker and Kubernetes.
This guide is designed to be a hands-on, step-by-step walkthrough that addresses real-world challenges and production concerns.
2. Ideation and Requirements
2.1 Problem Statement
Develop a highly personalized movie recommendation system to improve content discovery and user engagement. The system should support real-time updates and scale from an MVP (100 concurrent users) to millions of users.
2.2 Goals
Personalization: Tailor movie suggestions to individual users using both movie metadata and interaction history.
Scalability: Begin with an MVP and design for future scalability.
Performance: Achieve sub-100ms latency for recommendation queries.
Security: Enforce strong access control and secure data exchange.
Resilience: Ensure high availability and fault tolerance through robust operational practices.
2.3 Functional Requirements
User Management:
Implement OAuth2 for authentication and role-based access control (RBAC).
Movie Data Management:
Ingest movie metadata from the TMDb API and store it in a relational database (PostgreSQL/MySQL on AWS RDS).
User Interaction Tracking:
Capture and log user events (views, ratings, likes/dislikes) with timestamps.
Embedding Generation:
Generate movie embeddings (using Sentence Transformers) and user embeddings (via a Two-Tower model with attention/time-decay).
Vector Database Integration:
Use FAISS for fast k-NN search and address its limitations (non-persistence, multi-replica divergence) via a centralized singleton service, persistent snapshots to S3, and Redis-backed caching.
Recommendation Logic:
Retrieve cached user embeddings, query the centralized FAISS service, and rank results by similarity, popularity, and recency.
Real-Time API:
Provide a FastAPI REST endpoint secured with OAuth2 that returns recommendations in under 100ms.
(Optional) Frontend:
Build a simple user interface to browse movies and view recommendations.
2.4 Non-Functional Requirements
Scalability & Performance:
Architect the system to scale horizontally using Kubernetes autoscaling and distributed services.
Availability & Resilience:
Use health checks, readiness probes, and graceful shutdown mechanisms.
Security:
Use OAuth2, enforce RBAC, secure credentials via AWS Secrets Manager, and use IRSA for pod IAM roles.
Cost Optimization:
Implement autoscaling policies, leverage Spot Instances, and regularly review resource usage.
Cloud-Agnostic Design:
Use Infrastructure as Code (Terraform) to support future migration to Google Cloud if needed.
3. Design and Architecture
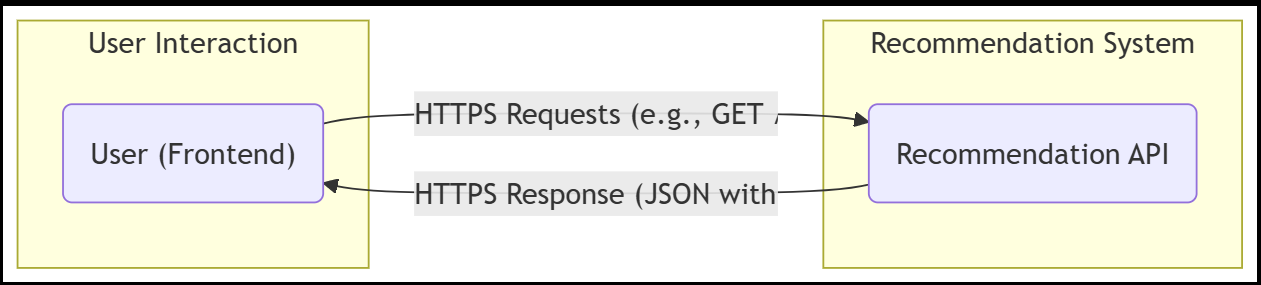
3.1 High-Level Architecture Overview
The following diagram shows the key components and data flows:

3.2 Key Architectural Decisions
Centralized FAISS Singleton Service:
Challenge: FAISS is not distributed, and each pod would otherwise have its in-memory index.
Solution: Run a dedicated FAISS service that all recommendation queries use. Use an init container to load the index from S3 at startup and periodically update it.
Real-Time Data Pipeline:
Challenge: Incorporating new movies and interactions into the index.
Solution: Use Kafka or AWS Kinesis to stream events, then trigger embedding updates and index refreshes.
Advanced User Embedding:
Challenge: Simple averaging yields low-quality embeddings.
Solution: Implement a two-tower neural network (with TensorFlow Recommenders or PyTorch) that uses weighted user interactions. Cache computed embeddings in Redis.
Security:
Use OAuth2 for authentication (via providers such as Auth0 or Keycloak), enforce RBAC, and secure credentials using AWS Secrets Manager and IRSA.
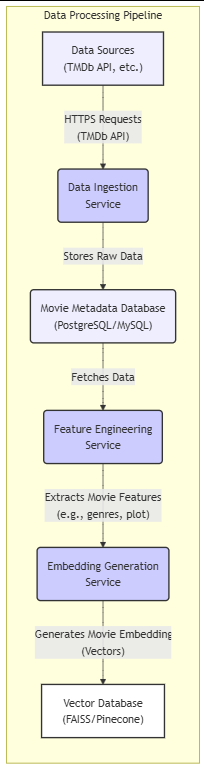
4. Development: Step-by-Step Implementation
This section details concrete code examples and configuration steps.
4.1 Data Ingestion
4.1.1 Fetching Movie Data from TMDb
tmdb_ingest.py:
import requests, time, logging
import psycopg2
from psycopg2.extras import execute_values
TMDB_API_KEY = "YOUR_TMDB_API_KEY"
BASE_URL = "https://api.themoviedb.org/3/movie/"
RATE_LIMIT = 4 # requests per second
def fetch_movie(movie_id):
url = f"{BASE_URL}{movie_id}?api_key={TMDB_API_KEY}"
response = requests.get(url)
if response.status_code != 200:
logging.error(f"Error fetching movie {movie_id}: {response.text}")
return None
return response.json()
def ingest_movies(movie_ids, conn):
data = []
for mid in movie_ids:
movie = fetch_movie(mid)
if movie:
data.append((
movie.get("id"),
movie.get("title"),
str([genre["name"] for genre in movie.get("genres", [])]),
movie.get("overview"),
int(movie.get("release_date", "0000")[:4]) if movie.get("release_date") else None
))
time.sleep(1.0 / RATE_LIMIT)
with conn.cursor() as cur:
sql = """
INSERT INTO movies (movie_id, title, genres, plot_summary, release_year)
VALUES %s
ON CONFLICT (movie_id) DO UPDATE SET
title = EXCLUDED.title,
genres = EXCLUDED.genres,
plot_summary = EXCLUDED.plot_summary,
release_year = EXCLUDED.release_year;
"""
execute_values(cur, sql, data)
conn.commit()
if __name__ == "__main__":
conn = psycopg2.connect(dbname="moviesdb", user="user", password="pass", host="your-rds-endpoint")
movie_ids = range(550, 560) # Example movie IDs
ingest_movies(movie_ids, conn)
conn.close()
Handling API errors, retries, and logging is essential for production.
4.1.2 Database Schema
SQL Schema for Movies:
CREATE TABLE movies (
movie_id INTEGER PRIMARY KEY,
title VARCHAR(255),
genres TEXT[],
plot_summary TEXT,
release_year INTEGER,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
4.2 User Interaction Tracking
user_tracking.py:
import psycopg2
def log_interaction(user_id, movie_id, interaction_type, rating=None):
conn = psycopg2.connect(dbname="moviesdb", user="user", password="pass", host="your-rds-endpoint")
with conn.cursor() as cur:
cur.execute("""
INSERT INTO user_interactions (user_id, movie_id, interaction_type, rating, timestamp)
VALUES (%s, %s, %s, %s, NOW());
""", (user_id, movie_id, interaction_type, rating))
conn.commit()
conn.close()
SQL Schema for User Interactions:
CREATE TABLE user_interactions (
id SERIAL PRIMARY KEY,
user_id INTEGER,
movie_id INTEGER,
interaction_type VARCHAR(50),
rating INTEGER,
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
4.3 Feature Engineering & Embedding Generation
4.3.1 Generating Movie Embeddings
movie_embedding.py:
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-mpnet-base-v2')
def generate_movie_embedding(plot_summary: str) -> np.ndarray:
embedding = model.encode(plot_summary)
return embedding.astype('float32')
# Example usage:
if __name__ == "__main__":
summary = "A young programmer is recruited by a mysterious organization."
emb = generate_movie_embedding(summary)
print("Embedding shape:", emb.shape)
4.3.2 Advanced User Embeddings with a Two-Tower Model
two_tower.py:
import tensorflow as tf
import tensorflow_recommenders as tfrs
# Define dummy parameters for demonstration
USER_VOCAB_SIZE = 10000
MOVIE_VOCAB_SIZE = 10000
EMBEDDING_DIM = 64
class UserModel(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
def call(self, inputs):
return self.embedding(inputs)
class MovieModel(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
def call(self, inputs):
return self.embedding(inputs)
class TwoTowerModel(tfrs.models.Model):
def __init__(self, user_model, movie_model):
super().__init__()
self.user_model = user_model
self.movie_model = movie_model
self.task = tfrs.tasks.Retrieval(metrics=tfrs.metrics.FactorizedTopK(candidates=[]))
def compute_loss(self, features, training=False):
user_embeddings = self.user_model(features["user_id"])
movie_embeddings = self.movie_model(features["movie_id"])
return self.task(user_embeddings, movie_embeddings)
# Training, evaluation, and saving the model should follow standard TF practices.
For production, include preprocessing of interaction data, a training loop, evaluation metrics (Precision@k, Recall@k), and periodic retraining to address cold-start issues.
4.3.3 Caching User Embeddings in Redis
cache_embeddings.py:
import redis
import pickle
# Connect to Redis (update host/port as necessary)
r = redis.Redis(host='redis-host', port=6379, db=0)
def cache_user_embedding(user_id, embedding):
r.set(f"user:{user_id}:embedding", pickle.dumps(embedding))
def get_cached_embedding(user_id):
data = r.get(f"user:{user_id}:embedding")
if data:
return pickle.loads(data)
return None
Decide on a cache invalidation strategy based on new interactions or periodic refreshes.
4.4 Vector Database Integration with FAISS
4.4.1 Creating and Persisting an FAISS Index
faiss_index.py:
import faiss
import numpy as np
import boto3
EMBEDDING_DIM = 768 # Adjust as per your model
def create_index(embeddings: np.ndarray):
index = faiss.IndexFlatL2(EMBEDDING_DIM)
index.add(embeddings)
return index
def save_index(index, s3_bucket, s3_key):
local_path = "/tmp/faiss.index"
faiss.write_index(index, local_path)
s3 = boto3.client('s3')
s3.upload_file(local_path, s3_bucket, s3_key)
def load_index(s3_bucket, s3_key):
local_path = "/tmp/faiss.index"
s3 = boto3.client('s3')
s3.download_file(s3_bucket, s3_key, local_path)
index = faiss.read_index(local_path)
return index
4.4.2 FAISS Singleton Service
faiss_service.py:
from fastapi import FastAPI, HTTPException
import faiss
import numpy as np
import uvicorn
from faiss_index import load_index
app = FastAPI()
# Global FAISS index variable
faiss_index = None
def load_faiss():
global faiss_index
s3_bucket = "your-bucket"
s3_key = "faiss.index"
faiss_index = load_index(s3_bucket, s3_key)
@app.on_event("startup")
def startup_event():
load_faiss()
@app.get("/query")
def query_index(embedding: list, k: int = 10):
if faiss_index is None:
raise HTTPException(status_code=500, detail="Index not loaded")
query_vector = np.array([embedding], dtype='float32')
distances, indices = faiss_index.search(query_vector, k)
return {"indices": indices.tolist(), "distances": distances.tolist()}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=9000)
Ensure this service is secured and monitored in production.
4.5 Recommendation API Development
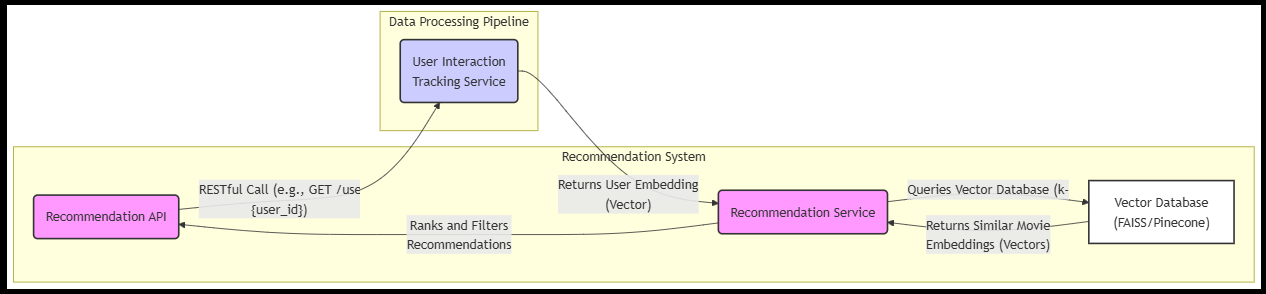
recommendation_api.py:
from fastapi import FastAPI, HTTPException, Depends
from fastapi.security import OAuth2PasswordBearer
import redis
import pickle
import requests
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
r = redis.Redis(host='redis-host', port=6379, db=0)
def get_user_embedding(user_id: int):
data = r.get(f"user:{user_id}:embedding")
if data:
return pickle.loads(data)
else:
raise HTTPException(status_code=404, detail="User embedding not found")
def query_faiss(embedding):
url = "http://faiss-service:9000/query"
params = {"embedding": embedding.tolist(), "k": 10}
response = requests.get(url, params=params)
if response.status_code != 200:
raise HTTPException(status_code=500, detail="Error querying FAISS")
return response.json()
@app.get("/recommendations/{user_id}")
async def recommendations(user_id: int, token: str = Depends(oauth2_scheme)):
# Validate token with an OAuth2 provider (implementation omitted for brevity)
user_embedding = get_user_embedding(user_id)
faiss_result = query_faiss(user_embedding)
# Optionally, merge results with RDS data for ranking refinements
return {"recommended_movie_ids": faiss_result["indices"][0]}
@app.get("/health")
def health():
return {"status": "ok"}
Integrate full OAuth2 middleware and RBAC for production security.
5. Deployment on AWS with Docker and Kubernetes
5.1 Dockerization
Create Dockerfiles for each service. For example, the Recommendation API Dockerfile:
Dockerfile:
FROM python:3.9-slim-buster
RUN apt-get update && apt-get install -y build-essential
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY ./app /app
WORKDIR /app
EXPOSE 8000
CMD ["uvicorn", "recommendation_api:app", "--host", "0.0.0.0", "--port", "8000"]
Push these images to AWS ECR.
5.2 Kubernetes Setup on AWS (EKS)
Create an EKS cluster using eksctl:
eksctl create cluster --name movie-recommender --region us-east-1 --nodegroup-name standard-workers --node-type t3.medium --nodes 2 --nodes-min 2 --nodes-max 4
Configure kubectl to use your new cluster.
5.3 Kubernetes Deployment Manifests
recommendation-deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: recommendation-api
spec:
replicas: 2
selector:
matchLabels:
app: recommendation-api
template:
metadata:
labels:
app: recommendation-api
spec:
containers:
- name: recommendation-api
image: your-ecr-repo/recommendation-api:latest
ports:
- containerPort: 8000
env:
- name: VECTOR_DB_TYPE
value: "faiss"
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 10
periodSeconds: 5
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 20
periodSeconds: 10
initContainers:
- name: load-faiss-index
image: amazon/aws-cli
command: ["aws", "s3", "cp", "s3://your-bucket/faiss.index", "/data/faiss.index"]
volumeMounts:
- mountPath: /data
name: faiss-index
volumes:
- name: faiss-index
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: recommendation-api-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8000
selector:
app: recommendation-api
5.4 AWS Services Configuration
EKS: Use managed node groups (e.g., t3.medium, with autoscaling and possibly Spot Instances).
RDS: Deploy a PostgreSQL/MySQL instance (e.g., db.t3.medium) with proper security groups.
S3: Create a bucket for FAISS index snapshots and other assets.
IAM & Security:
Use IRSA for Kubernetes pods to access AWS resources.
Configure AWS Secrets Manager for storing sensitive credentials.
ALB & Autoscaling:
The Kubernetes service type LoadBalancer provisions an ALB.
Use HPA for pods and Cluster Autoscaler for EC2 nodes.
6. Transition to Pinecone and Future Migration
Abstract the Vector DB Interface:
Define a common interface (e.g.,
VectorDB) with methods likeadd(),search(),persist(), etc.
Implement Dual-Writing:
During migration, write to both FAISS and Pinecone to ensure data consistency.
Terraform:
Use Terraform scripts to define your AWS (or GCP) infrastructure in a cloud-agnostic manner.
7. Operational Excellence
7.1 Testing & Monitoring
A/B Testing:
Implement experiments to measure recommendation quality (Precision@k, Recall@k).
Monitoring:
Use AWS CloudWatch and Prometheus/Grafana dashboards to monitor latency, error rates, and system health.
CI/CD:
Set up GitHub Actions or AWS CodePipeline for automatic builds, tests, and deployments.
Deployment Strategies:
Use canary deployments or blue-green deployments to minimize risk.
7.2 Cost Optimization
Use autoscaling for pods and EC2 nodes.
Leverage Spot Instances where possible.
Regularly review AWS cost reports and optimize resource usage.
8. Conclusion
This production-ready guide has provided a detailed, step-by-step blueprint for building a Netflix-like movie recommendation system on AWS.
By addressing the challenges of FAISS persistence, implementing advanced two-tower embedding models with proper caching, integrating robust security measures, and deploying via Docker and Kubernetes, you now have a comprehensive roadmap for both an MVP and eventual production deployment.
With strategies for real-time updates, dual-writing for migration to Pinecone, and operational monitoring, this blueprint transforms an initial prototype into a battle-tested solution.
Adapt the code examples, configuration details, and operational practices provided here to suit your environment and requirements.
Happy coding, deploying, and iterating on your recommendation system!
Like/subscribe/share
Thank you, contact us for further help/support required
 | A guest post by
|
 | A guest post by
|