

Unlock Enterprise-Scale Semantic Search: LlamaIndex Secrets
Tired of enterprise search that misses the point? In Part 3 of our series, we dive into unlocking enterprise-scale semantic search with LlamaIndex.

Imagine a search that truly understands meaning, not just keywords, and scales effortlessly with your growing data. LlamaIndex, a flexible framework connecting LLMs to your data, empowers you to build state-of-the-art Q&A systems and NLP solutions. Ready to move beyond keyword limitations and implement truly intelligent search across your enterprise data? Let’s explore how LlamaIndex makes scalable semantic search a reality.
Project Overview
In today’s data-driven environment, transforming a prototype into a production-ready system is key to delivering real business value. Imagine a semantic search engine that can rapidly sift through massive datasets—ranging from legal documents to financial records—extracting critical insights in seconds. Our MVP is a semantic search engine that ingests data from multiple sources, indexes it efficiently, and exposes its functionality via a secure, scalable REST API. This system not only speeds up data retrieval but also serves as a robust foundation for future innovations.
System Architecture
Our production system is engineered for scalability and reliability. Key components include:
Data Ingestion Layer: Handles data from files, databases, cloud storage, and streaming platforms with robust validation, transformation (e.g., using Pandas), and schema management.
Indexing Layer: Utilizes advanced index types (VectorStoreIndex, TreeIndex, KeywordTableIndex, ComposableIndex) chosen based on trade-offs between indexing speed, query performance, and memory usage.
API Layer: Exposes LlamaIndex functionality via a REST API with robust versioning, authentication, rate limiting, and error handling.
LLM Integration: Supplies structured, context-rich data to various LLMs, optimizing prompt engineering and handling token limits.
Monitoring & Logging: Continuously tracks performance metrics, error rates, and resource usage with distributed tracking and dashboards.
Deployment & Security: Ensures secure deployments via Docker containers on cloud platforms (AWS ECS, Google Cloud Run, Azure) with best practices in endpoint security and configuration management.
Code Implementation (Production-Ready)
Transforming our design into production code means following best practices across all layers.
Robust Data Ingestion
Our ingestion layer integrates data from diverse sources. For example, ingest data from local files, databases, and APIs while performing validation and transformation:
import logging
import requests
import pandas as pd
from llama_index.core import Document, FileDataConnector
from llama_index.readers.json import JSONReader
logging.basicConfig(level=logging.INFO)
def load_local_data(file_path):
try:
# Example using Pandas for CSV files
df = pd.read_csv(file_path)
documents = [Document(text=row["content"]) for _, row in df.iterrows()]
logging.info("Local data loaded from %s", file_path)
return documents
except Exception as e:
logging.error("Error loading local data: %s", e)
return []
def load_api_data(api_url):
try:
response = requests.get(api_url, timeout=10)
response.raise_for_status()
data = JSONReader().load_data(response.json())
logging.info("API data loaded successfully from %s", api_url)
return data
except requests.exceptions.RequestException as e:
logging.error("Error fetching API data: %s", e)
return []
documents = load_local_data("data/large_dataset.csv")
api_documents = load_api_data("https://api.example.com/data")Optimized Indexing
Choose the right index based on your data and query requirements. For semantic search, we use VectorStoreIndex while also combining indexes for hybrid approaches.
from llama_index.core import VectorStoreIndex, TreeIndex, KeywordTableIndex, ComposableIndex
vector_index = VectorStoreIndex.from_documents(documents)
logging.info("VectorStoreIndex created with %d documents", len(documents))
tree_index = TreeIndex.from_documents(documents)
keyword_index = KeywordTableIndex.from_documents([Document(text="keyword sample") for _ in range(3)])
composite_index = ComposableIndex(indexes=[vector_index, tree_index, keyword_index])
logging.info("Composite Index created with %d sub-indexes", len(composite_index.indexes))API Development
A robust REST API is critical. Below is an example using FastAPI, with versioning, JWT authentication, rate limiting, and input validation using Pydantic.
from fastapi import FastAPI, HTTPException, Depends
from fastapi.middleware.cors import CORSMiddleware
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
import os
app = FastAPI(title="LlamaIndex Production API", version="1.0.0")
app.add_middleware(CORSMiddleware, allow_origins=["*"])
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
API_SECRET_KEY = os.getenv("API_SECRET_KEY")
class QueryRequest(BaseModel):
query: str
@app.post("/v1/search")
async def search_documents(request: QueryRequest, token: str = Depends(oauth2_scheme)):
# Validate JWT token (placeholder for real JWT validation)
try:
query_engine = composite_index.as_query_engine()
results = query_engine.query(request.query)
return {"results": results}
except Exception as e:
logging.error("Search error: %s", e)
raise HTTPException(status_code=500, detail="Internal Server Error")Error Handling, Logging, and Security
Ensure every component has robust error handling and logging. Use structured logging and secure API key management (e.g., via HashiCorp Vault).
import os
# Example: Securely load API keys from environment variables and enforce HTTPS
API_SECRET_KEY = os.getenv("API_SECRET_KEY")Deployment
Containerize your application with Docker and use Terraform for infrastructure management. Below is a sample Dockerfile and Terraform snippet.
Dockerfile:
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]Terraform (AWS ECS):
resource "aws_ecs_cluster" "llamaindex" {
name = "llamaindex-cluster"
}Testing
Adopt a comprehensive testing strategy. Use pytest and unittest.mock for unit, integration, and end-to-end tests.
from unittest.mock import patch
import pytest
@patch("requests.get")
def test_api_ingestion(mock_get):
mock_get.return_value.status_code = 200
data = load_api_data("https://api.example.com/data")
assert data is not NoneMonitoring and Observability
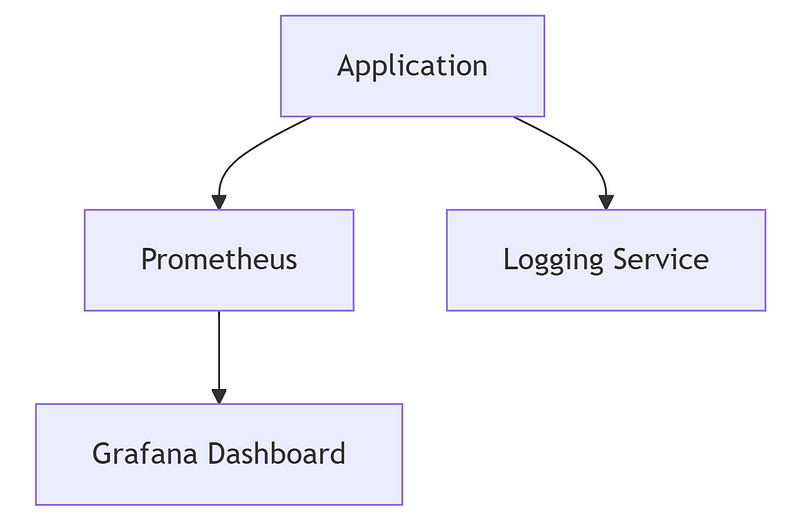
Set up monitoring with Prometheus and Grafana to track latency, throughput, error rates, and resource usage. Use distributed tracing tools like Jaeger.
Monitoring Diagram:
MVP and Demo
Our MVP is a fully functional semantic search engine. Users can query the system via the REST API, and a live demo is available via Streamlit.
import streamlit as st
st.header("Live Semantic Search")
query = st.text_input("Enter query:")
if query:
st.write(vector_index.query(query))Live Demo (placeholder)
Future Enhancements
Future work may include:
Asynchronous data ingestion and processing
Advanced caching strategies (using Redis or Memcached)
Enhanced prompt engineering and multi-LLM integration
Real-time monitoring with distributed tracing and alerting
Conclusion and Call to Action
Building a production-grade LlamaIndex application requires meticulous attention to data ingestion, indexing, API design, security, testing, and monitoring. Our semantic search engine demonstrates these principles, significantly improving data retrieval efficiency and delivering real business value. I invite you to experiment with these techniques, refine them to your needs, and contribute to our open-source community. Explore our GitHub repository and join our Discord community for collaboration.
Call to Action:
Download our free Production Readiness Checklist, join our challenge project, and start building your own scalable LlamaIndex application today!
FAQs
What is the MVP for this production-grade application?
It is a semantic search engine that ingests large datasets and provides fast, accurate search results via a secure REST API.How does the system architecture support scalability?
The architecture separates data ingestion, indexing, query processing, and API layers, enabling independent scaling and cloud deployment.What testing strategies are recommended?
A comprehensive approach using unit, integration, and end-to-end tests with frameworks like pytest and mock-based testing.How are security concerns addressed?
Through HTTPS, JWT authentication, CORS, input sanitization, and secure management of API keys.What future enhancements are planned?
Enhancements include asynchronous processing, advanced caching, multi-LLM integration, and real-time monitoring with distributed tracing.
Troubleshooting Appendix
Schema conflict error in Weaviate:
Delete the existing class before re-creating it:
client.schema.delete_class("Document")Performance Tuning Checklist:
Optimize chunk sizes and batch processing
Monitor memory usage and query latency
Adjust indexing configurations based on benchmarks
Version Compatibility Table:
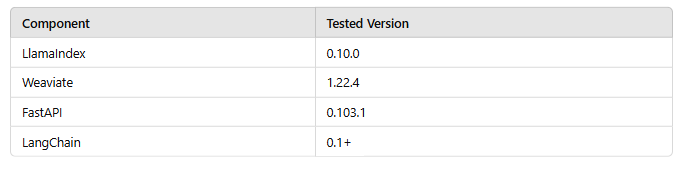
Version Compatibility and Ethical AI
Ethical AI Considerations:
Regularly audit search results for bias, anonymize sensitive data, and follow guidelines for responsible AI use.